ARM接口编程
《ARM接口编程》以开发板为线索,详细介绍了常见的几种接口,主要内容包括嵌入式硬件概述,GPIO接口编程,UART串口通信,AD转换接口,中断INT接口,RTC实时时钟单元等。《ARM接口编程》的实验都以"理论+在线仿真实践"的方法贯穿始终,从简单到复杂,循序渐进,层层深入。
-

选择特殊符号
选择搜索类型
请输入搜索
《ARM接口编程》以开发板为线索,详细介绍了常见的几种接口,主要内容包括嵌入式硬件概述,GPIO接口编程,UART串口通信,AD转换接口,中断INT接口,RTC实时时钟单元等。《ARM接口编程》的实验都以"理论+在线仿真实践"的方法贯穿始终,从简单到复杂,循序渐进,层层深入。
第1章 嵌入式硬件概述
1.1 硬件产品设计流程
1.2 电路图的识图能力
1.3 软件控制硬件方法
1.4 嵌入式C语言
1.4.1 寄存器定义解释
1.4.2 寄存器操作
1.52440SDK底板接口资源说明
1.6 本章小结
1.7 课后练习
第2章 GPIO接口编程
2.1 GPIO接口介绍
2.1.1 I/O接口的编址方式
2.1.2 GPIO(General-Purpose IO ports)
2.2 硬件原理分析
2.2.1 蜂鸣器硬件原理分析
2.2.2 LED的硬件原理分析
2.3 GPIO接口程序实现
2.3.1 基于GPIO接口的蜂鸣器控制实现
2.3.2 基于GPIO接口的LED控制实现
2.4 Keil MDK程序在线仿真调试环境配置
2.5 本章小结
2.6 课后练习
第3章 UART串口通信
3.1 通信的基本模式及原理
3.1.1 数据通信的基本模式
3.1.2 串行通信原理
3.2 串行通信的方式
3.2.1 同步串行通信
3.2.2 异步串行通信
3.3 串口硬件原理分析
3.3.1 RS-232-C接口
3.3.2 UART数据流电路分析
3.4 串口通信程序设计
3.4.1 初始化UART端口
3.4.2 UART线性控制寄存器
3.4.3 UART控制寄存器
3.4.4 UART波特率除数寄存器(波特率因子寄存器)
3.5 本章小结
3.6 课后练习
第4章 AD转换接口
4.1 ADC介绍
4.1.1 AD转换器的分类
4.1.2 AD转换器的主要技术指标
4.2 A/D转换过程
4.3 模数(A/D)转换器工作原理
4.3.1 A/D转换工作原理
4.3.2 AD硬件原理
4.4 ADC程序设计
4.5 本章小结
4.6 课后练习
第5章 中断INT接口
5.1 S3C2440中断介绍
5.2 中断控制器操作
5.3 ARM中断异常处理
5.3.1 ARM中断异常处理流程
5.3.2 中断优先级生成模块
5.4 看门狗中断程序实例
5.4.1 看门狗概念
5.4.2 看门狗的功能模块及所用寄存器
5.4.3 看门狗程序实现
5.5 键盘中断程序设计
5.5.1 键盘中断硬件连接
5.5.2 键盘中断程序的实现
5.6 本章小结
5.7 课后练习
第6章 RTC实时时钟
6.1 实时时钟介绍
6.2 S3C2440内部RTC模块结构框架分析
6.3 S3C2440处理器的RTC工作原理
6.4 RTC硬件原理及程序实现
6.4.1 RTC硬件原理
6.4.2 RTC程序实现
6.5 本章小结
6.6 课后练习
第7章 触摸屏接口
7.1 触摸屏介绍
7.1.1 触摸屏简介
7.1.2 触摸屏的主要类型
7.2 四线电阻式触摸屏的工作原理
7.2.1 触摸屏的接口部分
7.2.2 触摸屏接口模式
7.2.3 触摸屏相关寄存器
7.3 触摸屏程序设计及实现
7.4 本章小结
7.5 课后练习
第8章 LCD显示屏接口
8.1 LCD显示屏介绍
8.1.1 超薄平面显示器时代来临
8.1.2 液晶的发明与原理
8.1.3 液晶显示器的发展与未来
8.2 S3C2440 LCD控制器详解
8.3 TFT屏时序分析及LCD控制器的设置方法
8.3.1 TFT屏时序分析
8.3.2 S3C2440 LCD控制器的设置方法
8.4 LCD驱动主程序分析
8.5 本章小结
8.6 课后练习
第9章 IIC接口控制
9.1 IIC概念及特点
9.1.1 IIC概念
9.1.2 IIC总线特点
9.1.3 I2C总线的硬件结构
9.2 IIC总线工作原理及工作时序
9.2.1 总线的构成及信号类型
9.2.2 IIC时序分析
9.3 S3C2440的硬件连接及IIC控制器
9.3.1 AT24××系列的硬件连接
9.3.2 S3C2440的IIC相关寄存器
9.4 IIC程序设计及实现
9.4.1 IIC程序设计
9.4.2 IIC程序实现
9.5 本章小结
9.6 课后练习
第10章 SD卡接口控制
10.1 SD总线接口
10.1.1 SPI接口
10.1.2 SD接口
10.2 SD总线协议
10.3 SD卡主程序分析
10.4 本章小结
10.5 课后练习
第11章 MMU内存管理单元
11.1 MMU介绍
11.2 S3C2440虚拟地址到物理地址的映射
11.2.1 虚拟地址和物理地址的概念
11.2.2 虚拟地址到物理地址的转换过程
11.2.3 内存的访问权限检查
11.2.4 TLB的作用
11.2.5 Cache的作用
11.2.6 S3C2440 MMU、TLB、Cache的控制指令
11.3 MMU使用实例--地址映射
11.4 本章小结
11.5 课后练习
第12章 ARM-Keil集成开发环境
12.1 Keil MDK特性
12.2 Keil MDK整体结构及应用开发解决方案
12.3 RealView MDK的使用
12.3.1 μVision4的安装
12.3.2 创建μVision4工程
12.4 Keil MDK编译器与ULINK2使用
12.4.1 ULINK2概述
12.4.2 ULINK2与MDK的链接使用
12.5 Keil MDK编译器与J-LINK使用
12.5.1 J-LINK概述
12.5.2 J-LINK与MDK的链接使用
12.6 Keil MDK编译器与H-JTAG使用
12.6.1 H-JTAG介绍
12.6.2 H-JTAG调试结构
12.6.3 H-JTAG的安装
12.6.4 H-JTAG配置
12.6.5 MDK的安装与设置
12.6.6 调试
12.7 本章小结
12.8 课后练习
附录
参考文献
你问的很抽象,看是什么牌子的plc,但是市面上见到的大部分plc都是可以用编程口来通讯,毕竟你编程监控什么的也都是要通讯的嘛。一般plc的编程口都是可以和触摸屏、上位机来通讯的,个别的除外。具体问题具...
public class LinkedList extends AbstractSequentialList implements List, Queue, ...
一般系统默认是SATA做主盘的 而且SATA没跳线设置! 主要的在主版COMS里面设置看看了!回答者:3683680 - 秀才 二级 8-20 17:08SATA硬盘BIOS设置图解分类:默认栏目 由...

 FoxPro应用程序编程接口及其库构造工具
FoxPro应用程序编程接口及其库构造工具
FoxPro应用程序编程接口及其库构造工具
本文介绍了利用VC开发FoxPro动态连接库的一般方法和相关软件环境的设置,并以一实例介绍了实现的过程。
OMRON PLC编程软件接口的研究
OMRON PLC编程软件接口的研究
通过对OMRONPLC编程软件CX Programmer采用的文本文件( .CXT)结构的分析,阐述了CXT文件的数据结构以及自动生成的方法,从而为用户将时序图无需编程转换成梯形图打下了基础,大大提高了PLC应用编程效率。
---
有同学反映,我们视频一上来就讲干货,希望适当普及一下相关概念,这篇就是。
ARM处理器解析
ARM9、ARM11是哈佛5级流水线结构,所以性能要高一点。ARM9和ARM11大多带内存管理器,跑操作系统好一点,ARM7适合裸奔。我们惯称的 ARM9系列中又存在ARM9与ARM9E两个系列,其中ARM9 属于ARM v4T架构,典型处理器如ARM9TDMI和ARM922T;
而ARM9E属于ARM v5TE架构,典型处理器如ARM926EJ和ARM946E。因为后者的芯片数量和应用更为广泛,所以我们提到ARM9的时候更多地是特指ARM9E系列处理器(主要就是ARM926EJ和ARM946E这两款处理器)。
下面关于ARM9的介绍也是更多地集中于ARM9E。
2
ARM7处理器和ARM9E处理器的流水线差别
对嵌入式系统设计者来说,硬件通常是第一考虑的因素。针对处理器来说,流水线则是硬件差别的最明显标志,不同的流水线设计会产生一系列硬件差异。
让我们来比较一下ARM7和ARM9E的流水线,ARM9E从ARM7的3级流水线增加到了5级,ARM9E的流水线中容纳了更多的逻辑操作,但是每一级的逻辑操作却变得更为简单。
比如原来 ARM7的第三级流水,需要先内部读取寄存器、然后进行相关的逻辑和算术运算,接着处理结果回写,完成的动作非常复杂;
而在ARM9E的5级流水中,寄存器读取、逻辑运算、结果回写分散在不同的流水当中,使得每一级流水处理的动作非常简洁。这就使得处理器的主频可以大幅度地提高。因为每一级流水都对应 CPU的一个时钟周期,如果一级流水中的逻辑过于复杂,使得执行时间居高不下,必然导致所需的时钟周期变长,造成CPU的主频不能提升。所以流水线的拉长,有利于CPU主频的提高。
在常用的芯片生产工艺下,ARM7一般运行在100MHz左右,而ARM9E则至少在200MHz以上。
3
ARM9E处理器的存储器子系统
像ARM926EJ 和ARM946E这两个最常见的ARM9E处理器中,都带有一套存储器子系统,以提高系统性能和支持大型操作系统。如图2所示,一个存储器子系统包含一个 MMU(存储器管理单元)或MPU(存储器保护单元)、高速缓存(Cache)和写缓冲(Write Buffer);CPU通过该子系统与系统存储器系统相连。
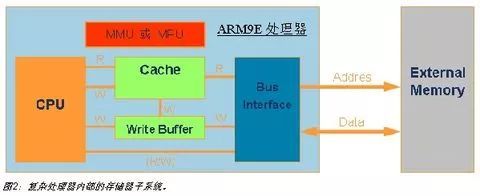
高速缓存和写缓存的引入是基于如下事实,即处理器速度远远高于存储器访问速度;如果存储器访问成为系统性能的瓶颈,则处理器再快也是浪费,因为处理器需要耗费大量的时间在等待存储器上面。
高速缓存正是用来解决这个问题,它可以存储最近常用的代码和数据,以最快的速度提供给CPU处理(CPU访问Cache不需要等待)。
4
复杂处理器内部的存储器子系统
MMU则是用来支持存储器管理的硬件单元,满足现代平台操作系统内存管理的需要;它主要包括两个功能:一是支持虚拟/物理地址映射,二是提供不同存储器地址空间的保护机制。
一个简单的例子可以帮助我们理解MMU的功能,在一个操作系统下,程序开发人员都是在操作系统给定的API和编程模型下开发程序;操作系统通常只开放一个确定的存储器地址空间给用户。这样就带来 一个直接的问题,所有的应用程序都使用了相同的存储器地址空间,如果这些程序同时启动的话(在现在的多任务系统中这是非常常见的),就会产生存储器访问冲 突。那操作系统是如何来避免这个问题的呢?
操作系统会利用MMU硬件单元完成存储器访问虚拟地址到物理地址的转换。所谓虚拟地址就是程序员在程序中使用的逻辑地址,而物理地址则是真实存储器单元的空间地址。MMU通过一定的规则, 可以把相同的虚拟地址映射到不同的物理地址上去。这样,即使有多个使用相同虚拟地址的程序进程启动,也可以通过MMU调度把它们映射到不同的物理地址上 去,不会造成系统错误。
5
MMU的功能和作用
MMU 处理地址映射功能之外,还能给不同的地址空间设置不同的访问属性。比如操作系统把自己的内核程序地址空间设置为用户模式下不可访问,这样的话用户应用程序就无法访问到该空间,从而保证操作系统内核的安全性。
MPU与MMU的区别在于它只有给地址空间设置访问属性的功能而没有地址映射功能。Cache以及MMU等硬件单元的引入,给系统程序员的编程模型带来了许多全新的变化。
除了需要掌握基本的概念和使用方法之外,下面几个针对系统优化的点既有趣又重要:
1.系统实时性考虑因素
为保存地址映射规则的页表(Page Table)非常庞大,通常MMU中只是存储器了常用的一小段页表内容,大部分页表内容都存储于主存储器里面;当调用新的地址映射规则时,MMU可能需要读取主存储器来更新页表。
这在某些情况下会造成系统实时性的丢失。比如当需要执行一段关键的程序代码时,如果不巧这段代码使用的地址空间不在当前MMU的页表处理范围里面,则MMU首先需要更新页表,然后完成地址映射,接着才能相应存储器访问;
整个地址译码过程非常长,给实时性带来非常大的不利影响。所以一般来说带MMU和Cache的系统在实时性上不如一些简单的处理器;不过也有一些办法能够帮助提高这些系统的实时效率。
一个简单的办法是在需要的时候关闭MMU和Cache,这样就变成一个简单处理器了,可以马上提高系统实时性。当然很多情况下这不可行;
在ARM的MMU和 Cache设计中,有一个锁定的功能,就是说你可以指定某一块页表在MMU中不会被更新掉,某一段代码或数据可以在Cache中锁定而不会被刷新掉;程序员可以利用这个功能来支持那些实时性要求最高的代码,保证这些代码始终能够得到最快的响应和支持。
2.系统软件优化
在嵌入式系统开发中,很多系统软件优化的方法都是相同和通用的,多数情况下这种规则也适用于ARM9E架构上。如果你已经是一个ARM7的编程高手,那么恭喜你,以前你掌握的优化方法完全可以用在新的ARM9E平台上,但是会有一些新的特性需要你加倍注意。最重要的便是Cache的作用,Cache本身并不 带来编程模型和接口的变化,但是如果我们考察Cache的行为,就能够发现对于软件优化,Cache是有比较大的影响的。
Cache在物理上就是一块高速SRAM,ARM9E的Cache组织宽度(cache line)都是4个word(也就是32个字节);Cache的行为受系统控制器控制而不是程序员,系统控制器会把最近访问存储器地址附近的内容复制到Cache中去,这样,当CPU访问下一个存储器单元的时候(这个访问既可能是取指,也可能是数据),可能这个存储器单元的内容已经在Cache里了,所以CPU不需要真的到主存储器上去读取内容,而直接读取Cache高速缓存上面的内容就可以了,从而加快了访问的速度。
从Cache的工作原理我们可以看 到,其实Cache的调度是基于概率的,CPU要访问的数据既可能在Cache中已经存在(Cache hit),也可能没有存在(Cache miss)。在Cache miss的情况下,CPU访问存储器的速度会比没有Cache的情况更坏,因为CPU除了要从存储器访问数据以外,还需要处理Cache hit或miss的判断,以及Cache内容的刷新等动作。
只有当Cache hit带来的好处超过Cache miss带来的牺牲的时候,系统的整体性能才能得到提高,所以Cache的命中率成为一个非常重要的优化指标。
根据Cache行为的特点,我们可以直观地得到提高Cache命中率的一些方法,如尽可能把功能相关的代码和数据放置在一起,减少跳转次数;跳转经常会引起 Cache miss。保持合适的函数大小,不要书写太多过小的函数体,因为线性的程序执行流程是最为Cache友好的。
循环体最好放置在4个word对齐的地址,这 样就能保证循环体在Cache中是行对齐的,并且占用最少的Cache行数,使得被多次调用的循环体得到更好的执行效率。
6
性能和效率的提升
前面介绍了ARM9E相比于ARM7性能上的提高,这不仅表现在ARM9E有更快的主频、更多的硬件特性上面,还体现在某些指令的执行效率上面。执行效率我 们可以用CPU的时钟周期数(Cycle)来衡量;
运行同一段程序,ARM9E的处理器可以比ARM7节省大约30%左右的时钟周期。
效率的提高主要来自于ARM9E对于Load-Store指令执行效率的增强。我们知道在RISC架构的处理器中,程序中大约有30%的指令是Load- Store指令,这些指令的效率对系统效率的贡献是最明显的。
ARM9E中有两个因素帮助提高Load-Store指令的效率:
1)ARM9内核是哈佛架构,拥有独立的指令和数据总线;相对应,ARM7内核的指令和数据总线复用的冯诺依曼架构。
2)ARM9的5级流水线设计把存储器访问和寄存器写回放在不同的流水上面。
两者结合,使得在指令流的执行过程中每个CPU时钟周期都可以完成一个Load或Store指令。
下面的表格比较了ARM7和ARM9处理器之间的Load -Store指令。
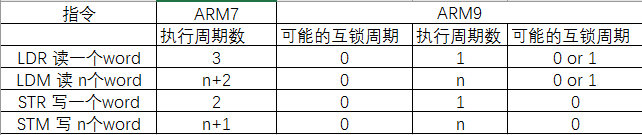
从中可以看出所有的Store指令ARM9比ARM7省1个周期,Load指令可以省2个周期(在没有互锁的情况下,编译工具能够通过 编译优化消除大多数的互锁可能)。
综合各种因素,ARM9E处理器拥有非常强大的性能。但是在实际的系统设计中,设计人员并不总是把处理器性能开到最大,理想情况是把处理器和系统运行频率降低,使得性能刚好能满足应用需求; 达到节省功耗和成本的目的。
在评估系统能够提供的处理器能力过程中,DMIPS指标被很多人采用; 同时它也被广泛应用于不同处理器间的性能比较。
但是用DMIPS来衡量处理器性能存在很大的缺陷。 DMIPS并非字面上每秒百万条指令的意思,它是一个测量CPU运行一个叫Dhrystone的测试程序时表现出来的相对性能高低的一个单位(很多场合人们也习惯用MIPS作为这个性能指标的单位)。因为基于程序的测试容易受到恶意优化的干扰,并且DMIPS指标值的发布不受任何机构的监督,所以使用DMIPS进行评估时要慎重。
例如对Dhrystone测试程序进行不同的编译处理,在同一个处理器上运行也可以得出差别很大的结果。
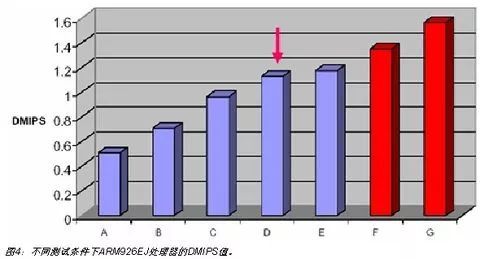
DMIPS另外一个缺点是不能测量处理器的数字信号处理能力和Cache/MMU子系统的性能。因为Dhrystone测试程序不包含DSP表达式,只包含一些整型运算和字符串处理,并且测试程序偏小,几乎可以完整地放在Cache里面运行而无需与外部存储器进行交互。这样就难以反映处理器在一个真实系统中的真正性 能。
一种值得鼓励的评估方法是站在系统的角度看问题,而不仅仅拘泥于CPU本身;而系统性能评估最好的测试向量就是用户应用程序或相近的测试程序,这是用户所需的最真实的结果。
7
ARM9E处理器的DSP运算能力
伴随应用程序的多样化和复杂化,诸如多媒体、音视频功能在嵌入式系统里面也是全面开花。这些应用需要相当的DSP处理能力;如果是在传统的RISC架构上实 现这些算法,所需的资源(频率和存储器等)会非常不经济。
ARM9E处理器一个非常重要的优势就是拥有轻量级的DSP处理能力,以非常小的成本(CPU增 加功能需要增加硬件)换来了非常实用的DSP性能。
因为CPU的DSP能力并不直接反映在像DMIPS这样的评测指标中,同时像以前的ARM7处理器中也没有类似的概念;所以这一点对所有使用ARM9E处理器进行开发的人来说,都是需要注意的一个要点。
ARM9E的DSP扩展指令,主要包括三个类型:
1)单周期的16x16和32x16 MAC操作,因为数字信号处理中甚少32位宽的操作数,在32位寄存器中可以对操作数分段运算显得非常有用。
2)对原有的算术运算指令增加了饱和处理扩展,所谓饱和运算,就是当运算结果大于一个上限或小于一个下限时,结果就等于上限或是下限;
饱和处理在音频数据和视频像素处理中普遍使用,现在一条单周期饱和运算指令就能够完成普通RISC指令“运算-判断-取值”这一系列操作。
3)前导零(CLZ)运算指令,提高了归一化和浮点运算以及除法操作的性能。
以流行的MP3解码程序为例。整个解码过程中前端的三个步骤是运算量最大的,包括比特流的读入(解包)、霍夫曼译码还有反量化采样(逆变换)。
ARM9E的 DSP指令正好可以高效地完成这些运算。以44.1 KHz@128 kbps码率的MP3音乐文件为例,ARM7TDMI需要占用20MHz以上的资源,
而ARM926EJ则只要小于10MHz的资源在从ARM7到ARM9的平台转变过程中,有一件事情是非常值得庆幸的,即ARM9E能够完全地向后兼容ARM7上的软件;并且开发人员面对的编程模型和架构基础也保持一致。
但是毕竟ARM9E中增加了很多新的特性,为了充分利用这些新的资源,把系统性能优化好,需要我们对ARM9E做更多深入地了解。
---end--


6月中旬来了,有同学询问我们的淘宝店铺是否搞降价活动,这里统一回复:产品定价已经很亲民,我们不打价格战,和往年一样,不参加618大促,目前只有现金奖励活动(点击下面标题了解详情):
【有奖活动】完成课后作业:裸机测试界面, 赢取奖金2000元人民币,
按要求完成最高可获得2000元现金奖励~,适合时间充裕还可以赚外快补贴生活费的在校生,何乐而不为?
41人加群,据小编了解目前已有好几个人正在写代码...你还在等什么?
免责声明:本文系网络转载,有改动,版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将根据您提供的版权证明材料确认版权并支付稿酬或者删除内容。
第一,学习基本的单片机编程。
对于学硬件的人而言,必须先对硬件的基本使用方法有感性的认识,更必须深刻认识该硬件的控制方式,如果一开始就学linux系统、学移植那么只会马上就陷入一个很深的漩涡。我在刚刚开始学ARM的时候是选择ARM7(主要是当时ARM9还很贵),学ARM7的时候还是保持着学51单片机的思维,使用ADS 去编程,第一个实验就是控制 led。学过一段时间ARM的人都会笑这样很笨,实际上也不是,我倒是觉得有这个过程会好很多,因为无论做多复杂的系统最终都会落实到这些最底层的硬件控制,因此对这些硬件的控制有了感性的认识就好很多了 学习单片机的编程的同时要好好理解这个硬件的构架、控制原理,这些我称他为理解硬件。所谓的理解硬件就是说,理解这个硬件是怎么组织这么多资源的,这些资源又是怎么由cpu、由编程进行控制的。比如说,s3c2410中有AD转换器,有GPIO(通用IO口),还有nandflash控制器,这些东西都有一些寄存器来控制,这些寄存器都有一个地址,那么这些地址是什么意思?又怎么通过寄存器来控制这些外围设备的运转?还有,norflash内部的每一个单元在这个芯片的内存中都有一个相应的地址单元,那么这些地址与刚刚说的寄存器地址又有什么关系?他们是一样的吗?而与 norflash相对应的nandflash内部的储存单元并不是线性排放的,那么s3c2410怎么将nandflash的地址映射在内存空间上进行使用?或者简单地说应该怎么用nandflash?再有,使用ADS进对ARM9行编程时都需要使用到一个初始化的汇编文件,这个文件究竟有什么用?他里面的代码是什么意思?不要这个可以吗?诸如此类都是对硬件的理解,理解了这些东西就对硬件有很深的理解了,这对以后更深一步的学习将有很大的帮助,如果跳过这一步,我相信越往后学越会觉得迷茫,越觉得这写东西深不可测。因为,你的根基没打好。
第二,使用linux系统进行一些基本的实验。
在买一套板子的时候一般会提供一些linux的试验例程,好好做一段时间这个吧,这个过程也是很有意义的,也是为进一步的学习积累感性认识,你能想象一个从没有使用过linux系统的人能学好linux的编程吗?好好按照手册上的例程做一做里面的实验,虽然有点娃娃学走路,有点弱智,但是我想很多高手都会经历这个过程。 在这方面我们深蓝科技没有计划提供相应的例程,主要是开发板的提供商会提供很丰富的例程,我们不做重复工作,只提供他们没有的、最有价值的东西给大家。
第三,研究完整的linux系统的的运行过程。
所谓完整的linux系统包括哪些部分呢? 三部分:bootloader、linux kernel(linux内核)、rootfile(根文件系统)。 那么这3部分是怎么相互协作来构成这个系统的呢?各自有什么用呢?三者有什么联系?怎么联系?系统的执行流程又是怎么样的呢?搞清楚这个问题你对整个系统的运行就很清楚了,对于下一步制作这个linux系统就打下了另一个重要的根基。介绍这方面的资料网上可以挖掘到几吨,自己好好研究吧。
第四,开始做系统移植。
上面说到完整的linux有3部分,而且你也知道了他们之间的关系和作用,那么现在你要做的便是自己动手学会制作这些东西。 当然我不可能叫你编写这些代码,这不实现。事实上这个3者都能在网下载到相应的源代码,但是这个源代码不可能下载编译后就能在你的系统上运行,需要很多的修改,直到他能运行在你的板子上,这个修改的过程就叫移植。在进行移植的过程中你要学的东西很多,要懂的相关知识也很多,等你完成了这个过程你会发现你已经算是一个初出茅庐的高手了。 在这个过程中如果你很有研究精神的话你必然会想到看源代码。很多书介绍你怎么阅读linux源代码,我不提倡无目的地去看linux源代码,用许三多的话说,这没有意义。等你在做移植的时候你觉得你必须去看源代码时再去找基本好书看看,这里我推荐一本好书倪继利的《linux内核的分析与编程》,这是一本针对linux-2.6.11内核的书,说得很深,建议先提高自己的C语言编程水平再去看。 至于每个部分的移植网上也可以找到好多吨的资料,自己研究研究吧,不过要提醒的是,很多介绍自己经验的东西都或多或少有所保留,你按照他说的去做总有一些问题,但是他不会告诉你怎么解决,这时就要靠自己,如果自己都靠不住就找我一起研究研究吧,我也不能保证能解决你的问题,因为我未必遇到过你的问题,不过我相信能给你一点建议,也许有助你解决问题。 这一步的最终目的是,从源代码的官方主页上(都是外国的,悲哀)下载标准的源代码包,然后进行修改,最终运行在板子上。 盗用阿基米德的一句话:“给我一根网线,我能将linux搞定”。
第五,研究linux驱动程序的编写。
移植系统并不是最终的目的,最终的目的是开发产品,做项目,这些都要进行驱动程序的开发。Linux的驱动程序可以说是五花八门,linux2.4和 linux2.6的编写有相当大的区别,就是同为linux2.6但是不同版本间的驱动程序也有区别,因此编写linux的驱动程序变都不是那么容易的事情,对于最新版本的驱动程序的编写甚至还没有足够的参考资料。那么我的建议就是使用、移植一个不算很新的版本内核,这样到时学驱动的编程就有足够的资料了。 这部分的推荐书籍可以参考另一篇文章《推荐几本学习嵌入式linux的书籍》。 第六,研究应用程序的编写。 做作品做项目除了编写驱动程序,最后还要编写应用程序。现在的趋势是图形应用程序的开发,而图形应用程序中用得最多的还是qt/e函数库。我一直就使用这个函数库来开发自己的应用程序,不过我希望你能使用国产的MiniGUI函数库。盗用周杰伦的广告词就是“支持国产,支持MiniGUI”。 MiniGUI的编程比较相似Windows下的VC编程,比较容易上手,效果应该说是相当不错的,我曾使用过来开发ARM7的程序。记住,问题是学习的最好机会
ARM7简介
ARM7系列处理器是英国ARM公司设计的主流嵌入式处理器ARM7内核是0.9MIPS/MHz的三级流水线和冯·诺伊曼结构;ARM9内核是5级流水线,提供1.1MIPS/MHz的哈佛结构。ARM7没有MMU。
ARM7系列包括ARM7TDMI、ARM7TDMI-S、带有高速缓存处理器宏单元的ARM720T。该系列处理器提供Thumb16位压缩指令集和EmbededICE软件调试方式,适用于更大规模的SoC设计中。ARM7TDMI基于ARM体系结构V4版本,是目前低端的ARM核。
ARM7TDMI处理器是ARM通用32位微处理器家族的成员之一。它具有优异的性能,但功耗却很低,使用门的数量也很少。它属于精简指令集计算机(RISC),比复杂指令集计算机(CISC)要简单得多。这样的简化实现了:高的指令吞吐量;出色的实时中断响应;小的、高性价比的处理器宏单元。三级流水线:ARM7TDMI处理器使用流水线来增加处理器指令流的速度。这样可使几个操作同时进行,并使处理和存储器系统连续操作,能提供0.9MIPS/MHz的指令执行速度。ARM7TDMI的流水线分3级,分别为:取指、译码、执行。正常操作过程中,在执行一条指令的同时对下一条指令进行译码,并将第三条指令从存储器中取出。内同时有5个指令在执行。在同样的加工工艺下,ARM9TDMI处理器的时钟频率是ARM7TDMI的1.8~2.2倍。
ARM9简介
ARM9系列处理器是英国ARM公司设计的主流嵌入式处理器,主要包括ARM9TDMI和ARM9E-S等系列。
ARM9采用哈佛体系结构,指令和数据分属不同的总线,可以并行处理。在流水线上,ARM7是三级流水线,ARM9是五级流水线。由于结构不同,ARM7的执行效率低于ARM9。平时所说的ARM7、ARM9实际上指的是ARM7TDMI、ARM9TDMI软核,这种处理器软核并不带有MMU和cache,不能够运行诸如linux这样的嵌入式操作系统。而ARM公司对这种架构进行了扩展,所以有了ARM710T、ARM720T、ARM920T、ARM922T等带有MMU和cache的处理器内核。
ARM9处理能力
(1)时钟频率的提高
ARM7处理器采用3级流水线,而ARM9采用5级流水线。增加的流水线设计提高了时钟频率和并行处理能力。5级流水线能够将每一个指令处理分配到5个时钟周期内,在每一个时钟周期内同时有5个指令在执行。在同样的加工工艺下,ARM9TDMI处理器的时钟频率是ARM7TDMI的1.8~2.2倍。
(2)指令周期的改进
指令周期的改进对于处理器性能的提高有很大的帮助。性能提高的幅度依赖于代码执行时指令的重叠,这实际上是程序本身的问题。对于采用最高级的语言,一般来说,性能的提高在30%左右。
UCOS简介
μC/OS II(Micro-Controller OperaTIng System Two)是一个可以基于ROM运行的、可裁剪的、抢占式、实时多任务内核,具有高度可移植性,特别适合于微处理器和控制器,适合很多商业操作系统性能相当的实时操作系统(RTOS)。为了提供最好的移植性能,μC/OS II最大程度上使用ANSI C语言进行开发,并且已经移植到近40多种处理器体系上,涵盖了从8位到64位各种CPU(包括DSP)。 μC/OS II可以简单的视为一个多任务调度器,在这个任务调度器之上完善并添加了和多任务操作系统相关的系统服务,如信号量、邮箱等。其主要特点有公开源代码,代码结构清晰、明了,注释详尽,组织有条理,可移植性好,可裁剪,可固化。内核属于抢占式,最多可以管理60个任务。从1992年开始,由于高度可靠性、鲁棒性和安全性,μC/OS II已经广泛使用在从照相机到航空电子产品的各种应用中。
μC/OS-II实时多任务操作系统内核。它被广泛应用于微处理器、微控制器和数字信号处理器。 μC/OS-II 的前身是μC/OS,最早出自于1992 年美国嵌入式系统专家Jean J.Labrosse 在《嵌入式系统编程》杂志的5 月和6 月刊上刊登的文章连载,并把μC/OS 的源码发布在该杂志的B B S 上。
UCOS应用情况
1) 高优先级的任务因为需要某种临界资源,主动请求挂起,让出处理器,此时将调度就绪状态的低优先级任务获得执行,这种调度也称为任务级的上下文切换。
2) 高优先级的任务因为时钟节拍到来,在时钟中断的处理程序中,内核发现高优先级任务获得了执行条件(如休眠的时钟到时),则在中断态直接切换到高优先级任务执行。这种调度也称为中断级的上下文切换。 这两种调度方式在μC/OS-II的执行过程中非常普遍,一般来说前者发生在系统服务中,后者发生在时钟中断的服务程序中。 调度工作的内容可以分为两部分:最高优先级任务的寻找和任务切换。其最高优先级任务的寻找是通过建立就绪任务表来实现的。μ C / O S 中的每一个任务都有独立的堆栈空间,并有一个称为任务控制块TCB(Task Control Block)的数据结构,其中第一个成员变量就是保存的任务堆栈指针。任务调度模块首先用变量OSTCBHighRdy 记录当前最高级就绪任务的TCB 地址,然后调用OS_TASK_SW函数来进行任务切换。