作者:熊中哲(沃趣科技)
邮箱:orain.xiong@woqutech.com,欢迎交流~
导 语
前文数据库容器化|未来已来我们介绍了基于Kubernetes实现的下一代私有 RDS。其中,调度策略是具体实现时至关重要的一环,它关系到RDS集群的服务质量和部署密度。那么,RDS需要怎样的调度策略呢?本文通过数据库的视角结合Kubernetes的源码,分享一下我的理解。
It was the best of times, it was the worst of times。
—by Dickens.
人类从爬行到直立用了几百万年,但是我们这些码农从Bare Metal到 Container只花了几万分之一的时间。

我有个朋友是维护Mainframe的,他还在使用40年前的系统。
调度策略很重要
看看巨人们在干什么,有助于我们更好的理解这个世界。
Google Borg
先看看Google是如何看待Borg(Kubernetes 的前身)的核心价值。在Google paper <Large-scale cluster management at Google with Borg>中,开篇就定义了 Borg:
It achieves high utilization by combining admission control, efficient task-packing,over-commitment, and machine sharing with process-level performance isolation.
里面还专门介绍了基于CPI (Cycles Per Instruction)测量资源利用率的方式。
AWS RDS
再看看公有云的领头羊, AWS是这样描述其RDS产品的:

不管是Google Borg还是AWS,除了提供更灵活,更开放,更兼容,更安全,可用性更高的系统,都将cost-efficient,high utilization放到了更重要的位置。
提高部署密度,减少硬件的需求量,最终达到降低硬件投入的目标。
同时,
必须满足业务需求。
本文尝试以数据库的视角,从多个角度阐述RDS场景需要怎样的调度策略。
说明:
为了实现更精细化的调度策略,Kubernetes(版本1.7) 调度器提供了17个调度算法。这些算法分为两类Predicate和Priority,通俗的描述是过滤和打分。设计思路大致如下:
1.通过过滤算法,从集群中出满足条件的节点;
2.通过打分算法,对过滤出来的节点打分并排名;
3.挑出分数最高的节点,如果有分数相同的,随机挑一个。
本文将基于Kubernetes的实现,结合RDS场景展开,并不会把所有的算法流水账似的写一遍,相关资料很多,有兴趣的同学可以去看文档。具体实现见:
① kubernetes/plugin/pkg/scheduler/algorithm/priorities
②kubernetes/plugin/pkg/scheduler/algorithm/predicates
下面进入主题。
调度策略
视角一 : 计算资源调度策略
这里讨论的计算资源仅包含 CPU,Memory:
需要特别说明,毕竟Kubernetes已经支持GPU。
看上去很简单,挑选出一个满足资源要求的节点即可,但是考虑到整合密度和数据库的业务特点并不简单,我们还需要考虑到以下几点:
峰值和均值:
数据库的负载随着业务、时间、周期不断变化,到底是基于峰值调度还是均值调度呢?这是一个有关部署密度的问题,最好的办法就像Linux里面限定资源的方式,让我们设置Soft Limit 和Hard Limit,以Soft Limit分配资源,同时Hard Limit又能限定使用的最大资源。Kubernetes也是这么做的,它会通过 Request 和 Limit 两个阈值来进行管理容器的资源使用。
Pod是Kubernetes的调度单位
Requst作为Pod初始分配值,Limit 限定了Pod能使用的最大值。分配时采用Requst值进行调度,这里有个假设:
同一节点上运行的容器不会同时达到 Limit 阈值
有效的实现了计算资源利用率的high utilization,非常适合数据库开发或测试场景。
如果假设不成立,
当某节点运行的所有容器同时接近Limit,并有将节点资源用完的趋势或者事实(在运行的过程中,调度器会定期收集所有节点的资源使用情况,“搜集”用词不太准确,但便于理解),创建 Pod的请求也不会再调度到该节点。

以内存为例, 当Pod的请求超出Node可以提供的内存, 会以异常的方式告知调度器, 内存资源不足
同时,基于优先级,部分容器将会被驱逐到其他节点(例如通过重启 Pod的方式),所以并不适合生产环境。
资源的平衡:
对于长期运行的集群,在满足资源的同时还要考虑到集群中各节点资源分配的平衡性。
类似Linux Buddy System,仅仅分配进程需要的内存是不够的,还要保障操作系统内存的连续性。
举个例子,RDS集群有两个节点,用户向RDS申请 2颗CPU和4GB内存 以创建 MySQL实例,两节点资源使用情况如下:
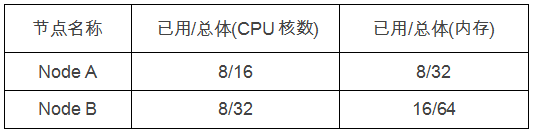
在资源同时满足的情况下,调度会通过两个公式对节点打分。
基于已使用资源比率(Balanced Resource)打分,实现如下:
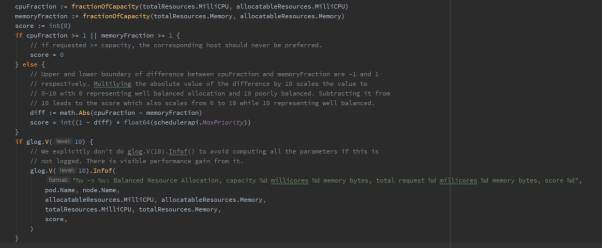
将节点资源输入公式,可简化成:
NodeA 分数 = int(1-math.Abs(8/16 - 8/32)) * float64(10) = 30/4
NodeB 分数 = int(1-math.Abs(8/32 - 16/64)) * float64(10) = 10
基于该算法Node B的分数更高。
再通过未使用资源(calculateUnused)持续打分。

该算法可简化成:
cpu((capacity - sum(requested)) * 10 / capacity) + memory((capacity - sum(requested)) * 10 / capacity) / 2
有兴趣的同学可以算一下,不再赘述。
数据库会被调度到综合打分最高的节点。
视角二 : 存储资源调度策略
存储资源是有状态服务中至关重要的一环,也让有状态服务的实现难度远超无状态服务。
除了满足请求数据库的存储资源的容量要求,调度策略必须要能够识别底层的存储架构和存储负载,在提供存储资源的同时,满足数据库的业务需求(比如数据零丢失和高可用)。
从2017年年初开始,基于分布式存储技术,我们的RDS已经实现了计算和存储分离的架构。
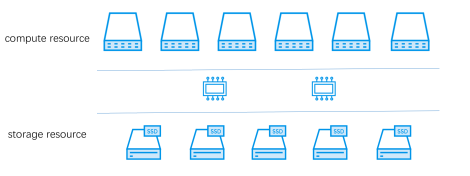
计算存储分离
在实现数据库的数据零丢失,高可用的同时,架构变得更通用,更简单。但对企业级用户,还远远不够,cost-efficient 是考量产品成熟度的重要因素。
所以从一开始,我们就以3种维度的存储QoS来思考这个问题:
从功能角度 :
存储资源分成两大类
distribution,基于分布式存储技术实现,对 Flash 设备做了专门的 优化,提供数据冗余和弹性扩容功能;
local,使用计算节点本地存储。
对于生产环境,我们会申请distribution资源。而那些不太重要的或者临时性的,譬如有的客户需要经常生成临时性的克隆库进行测试,或者扩展临时备库以应对突发的业务高峰,我们会申请local资源。
从性能角度:
我们又将distribution分成了两类high和medium,以应业务不同的IOPS,Through put,Latency需求。
IO密集型业务,我们会分配high类型。对于计算密集型或者重要值很高的备库,我们会分配medium类型。
从数据库角度:
比如, 不同的数据库物理卷的挂载参数也不同;
如果调度器能够实现, 将极大的提高存储资源的cost-efficient。
这些特性带有明显的数据库业务特性,原生的Kubernetes调度器并不支持。但是,我们通过二次开发,Out of Cluster的方式实现了外置的Kubernetes storage provisoner,并通过自定义的参数和代码实现和调度器的交互。

Kubernetes会使用我们提供的storage provisoner创建存储资源.
这样Kubernetes的调度器就可以基于RDS的业务需求,感知底层存储架构,提供满足业务需求的调度服务。
除去需要的容量信息,需要传递给调度器如下信息(就像请CPU,Memory资源一样):
volume.beta.kubernetes.io/mount-options: sync
volume.orain.com/storage-type: "distribution"
volume.orain.com/storage-qos: "high"
volume.orain.com/dc-id: "278"
通过这四个参数将会告知。
从功能角度:
volume.orain.com/storage-type: "distribution", 使用 distribution 类型存储资源。
从性能角度:
volume.orain.com/storage-qos: "high", 从高性能存储池获取 Volume
从数据库角度:
volume.beta.kubernetes.io/mount-options: sync, 使用特定 mount 参数
volume.orain.com/dc-id: "278", 使用编号为278的 Volume
视角三 : 关系型数据库
关系型数据库是有状态服务,但要求更加复杂。比如我们提供了MySQL的Read Write Cluster(读写分离集群) 和Sharding Cluster (分库分表集群),每个数据库实例都有自己的角色。调度器必须感知集群角色以实现业务特点:
比如, 基于数据库角色, 我们有如下调度需求:
ReadWrite Cluster的Master和Slave不能调度到同一节点
Master的多个Slave不能调度到同一节点
Sharding Cluster的每个分片不能调度到同一节点
某些备份任务须调度到指定Slave所在的节点
…..
带有明显的业务(RDS)特点,原生Kuberentes的调度策略并不能识别这些角色和关系。
与此同时,容器的运行状态和RDS集群还在动态变化:
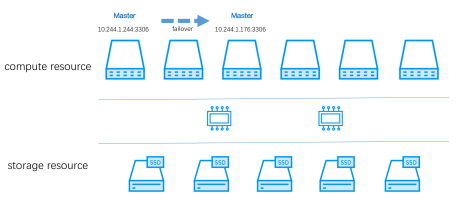
因 Failover迁移到其他节点
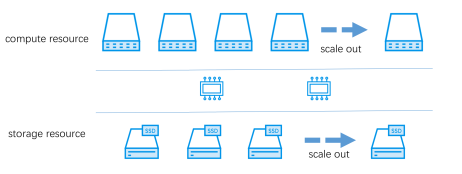
RDS集群 Scale Out
以上具体的问题抽象成:
亲和性(Affinity), 反亲和性(Anti-Affinity)和分布度(Spread Width)
再通过我们的二次开发,将数据库的角色和业务流程集成到调度器中,以满足全部需求。
亲和性(Affinity)
调度需求4可以归纳到这里
需求4 : 某些备份任务须调度到指定 Slave 所在的节点
在所有节点中找到指定 Slave 所在节点, 以确定待调度备份任务调度到哪个节点. 该需求必须满足, 不然备份任务无法成功.
建立已运行数据库和节点的关系,在通过Affinity和Anti-Affinity公式对所有节点打分,以此决定待调度数据库是否要调度到该节点。
查找该节点所有数据库实例:

确定该节点是否有指定 Slave:
反亲和性(Anti-Affinity)
需求1 : ReadWrite Cluster的 Master和 Slave不能调度到同一节点
以待调度数据库的角色为输入,建立已运行数据库和节点的关系,再通过 Anti-Affinity 公式对所有节点打分,以此决定待调度数据库是否要调度到该节点。
以需求1为例,统计集群成员的分布情况,该节点上同一数据库集群的成员越多,分数越低。
反亲和性(Anti-Affinity)公式
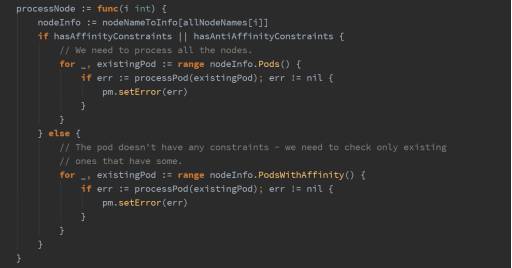
对所有节点打分
分布度(Spread Width)
有种更时髦的叫法散射度(scatter width)
需求2,3可以归纳到这里。
以需求2为例, 统计集群成员的分布情况, 该节点上同一数据库集群的成员越多, 分数越低。
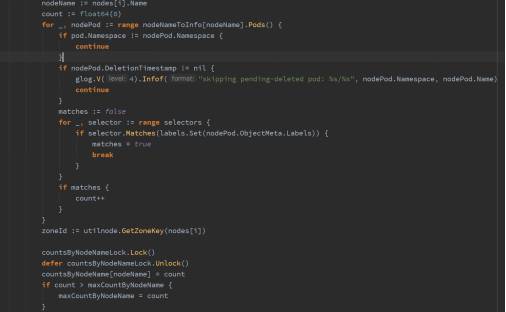
然后对所有节点打分,公式如下:
float64(schedulerapi.MaxPriority) * ((maxCountByNodeName -countsByNodeName[node.Name]) / maxCountByNodeName)
需要特别说明的是, 在RDS进行调度时:
需求1,4必须满足;
需求2,3尽量满足既可以。
必须和尽量也需要作为调度参数,让调度器知晓。
结 语
本文仅以RDS的视角,从三个层级讲述了对调度器的要求。
真实的世界会更加复杂,比如针对Read Write Cluster,Slave必须等待Master创建完毕,而Sharding Cluster,所有分片可以并发创建……
在设计产品和完成编码的过程中,踩坑无数。不能否认的是,站在巨人的肩膀上可以让我们看的更远。不知道Ending怎么写, 就这样吧。
BTW,如果你对我们正在做的事情感兴趣,投简历我吧:orain.xiong@gmail.com




知数堂

 混合机安装方
混合机安装方
 卧式双螺旋混合机设计
卧式双螺旋混合机设计