Bellman-Ford算法
Bellman - ford算法是求含负权图的单源最短路径的一种算法,效率较低,代码难度较小。其原理为连续进行松弛,在每次松弛时把每条边都更新一下,若在n-1次松弛后还能更新,则说明图中有负环,因此无法得出结果,否则就完成。
-
选择特殊符号
选择搜索类型
请输入搜索
Bellman - ford算法是求含负权图的单源最短路径的一种算法,效率较低,代码难度较小。其原理为连续进行松弛,在每次松弛时把每条边都更新一下,若在n-1次松弛后还能更新,则说明图中有负环,因此无法得出结果,否则就完成。
1.单源最短路径(从源点s到其它所有顶点v);
2.有向图&无向图(无向图可以看作(u,v),(v,u)同属于边集E的有向图);
3.边权可正可负(如有负权回路输出错误提示);
4.差分约束系统;
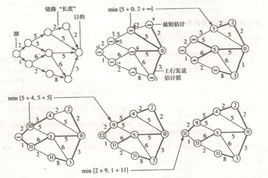
首先指出,图的任意一条最短路径既不能包含负权回路,也不会包含正权回路,因此它最多包含|v|-1条边。
其次,从源点s可达的所有顶点如果 存在最短路径,则这些最短路径构成一个以s为根的最短路径树。Bellman-Ford算法的迭代松弛操作,实际上就是按每个点实际的最短路径[虽然我们还不知道,但它一定存在]的层次,逐层生成这棵最短路径树的过程。
注意,每一次遍历,都可以从前一次遍历的基础上,找到此次遍历的部分点的单源最短路径。如:这是第i次遍历,那么,通过数学归纳法,若前面单源最短路径层次为1~(i-1)的点全部已经得到,而单源最短路径层次为i的点,必定可由单源最短路径层次为i-1的点集得到,从而在下一次遍历中充当前一次的点集,如此往复迭代,[v]-1次后,若无负权回路,则我们已经达到了所需的目的--得到每个点的单源最短路径。[注意:这棵树的每一次更新,可以将其中的某一个子树接到另一个点下]
反之,可证,若存在负权回路,第[v]次遍历一定存在更新,因为负权回路的环中,必定存在一个"断点",可用数学手段证明。
最后,我们在第[v]次更新中若没有新的松弛,则输出结果,若依然存在松弛,则输出'CAN'T'表示无解。同时,我们还可以通过"断点"找到负权回路。
1,.初始化:将除源点外的所有顶点的最短距离估计值 d[v] -->+∞, d[s]-->0;
2.迭代求解:反复对边集E中的每条边进行松弛操作,使得顶点集V中的每个顶点v的最短距离估计值逐步逼近其最短距离;(运行|v|-1次)
3.检验负权回路:判断边集E中的每一条边的两个端点是否收敛。如果存在未收敛的顶点,则算法返回false,表明问题无解;否则算法返回true,并且从源点可达的顶点v的最短距离保存在 d[v]中。
福特GT Ford GT早在许多年前,当初Ford原本打算买下Ferrari,好藉此进军超级跑车的市场。那个时候的Ferrari并没有现在这般地位。然而,就在交易完成的前一刻,Ferrari方面...
tom ford眼镜真假鉴别方法; 一,检查Tom Ford太阳镜的包装 还是那句话,真的包装物不能证明太阳镜一定是真的,但假的包装物则...
短跑的就是计算150厚度,按其水平投影面积计算,包含一半的梯井调出的板应该是单独计算,计入在挑檐板中吧
Dijkstra算法无法判断含负权边的图的最短路。如果遇到负权,在没有负权回路(回路的权值和为负,即便有负权的边)存在时,也可以采用Bellman - Ford算法正确求出最短路径。
Bellman-Ford算法能在更普遍的情况下(存在负权边)解决单源点最短路径问题。对于给定的带权(有向或无向)图 G=(V,E), 其源点为s,加权函数 w是 边集 E 的映射。对图G运行Bellman - Ford算法的结果是一个布尔值,表明图中是否存在着一个从源点s可达的负权回路。若不存在这样的回路,算法将给出从源点s到 图G的任意顶点v的最短路径d[v]。
For i:=1 to |V|-1 do
For 每条边(u,v)∈E do
Relax(u,v,w);
For每条边(u,v)∈E do
If dis[u]+w<dis[v] Then Exit(False)
bool Bellman-Ford(G,w,s) //图G ,边集 函数 w ,s为源点
1 for each vertex v ∈ V(G) //初始化 1阶段
2 d[v] ←+∞;
3 d[s] ←0; //1阶段结束
4 for(int i=1;i<|v|;i++) //2阶段开始,双重循环。
5 for each edge(u,v) ∈E(G) //边集数组要用到,穷举每条边。
6 if(d[v]> d[u]+ w(u,v))//松弛判断
7 d[v]=d[u]+w(u,v); //松弛操作2阶段结束
8 for each edge(u,v) ∈E(G)
9 if(d[v]> d[u]+ w(u,v))
10 return false;
11 return true;
算法时间复杂度O(VE)。因为算法简单,适用范围又广,虽然复杂度稍高,仍不失为一个很实用的算法。
SPFA算法
SPFA(Shortest Path Faster Algorithm)是Bellman-Ford算法的一种队列优化,减少了不必要的冗余计算。
{单源最短路径的Bellman-ford算法
执行v-1次,每次对每条边进行松弛操作
如有负权回路则输出"Error!!"}
算法大致流程是用一个队列来进行维护。 初始时将源加入队列。 每次从队列中取出一个元素,并对所有与他相邻的点进行松弛,若某个相邻的点松弛成功,则将其入队。 直到队列为空时算法结束。
分析 Bellman-Ford算法,不难看出,外层循环(迭代次数)|v|-1实际上取得是上限。由上面对算法正确性的证明可知,需要的迭代遍数等于最短路径树的高度。如果不存在负权回路,平均情况下的最短路径树的高度应该远远小于 |v|-1,在此情况下,多余最短路径树高的迭代遍数就是时间上的浪费,由此,可以依次来实施优化。
从细节上分析,如果在某一遍迭代中,算法描述中第7行的松弛操作未执行,说明该遍迭代所有的边都没有被松弛。可以证明(怎么证明?):至此后,边集中所有的边都不需要再被松弛,从而可以提前结束迭代过程。这样,优化的措施就非常简单了。
设定一个布尔型标志变量 relaxed,初值为false。在内层循环中,仅当有边被成功松弛时,将 relaxed 设置为true。如果没有边被松弛,则提前结束外层循环。这一改进可以极大的减少外层循环的迭代次数。优化后的 bellman-ford函数如下。
这样看似平凡的优化,会有怎样的效果呢?有研究表明,对于随机生成数据的平均情况,时间复杂度的估算公式为
1.13|E| if |E|<|V|
0.95*|E|*lg|V| if |E|>|V|
优化后的算法在处理有负权回路的测试数据时,由于每次都会有边被松弛,所以relaxed每次都会被置为true,因而不可能提前终止外层循环。这对应了最坏情况,其时间复杂度仍旧为O(VE)。
优化后的算法的时间复杂度已经和用二叉堆优化的Dijkstra算法相近了,而编码的复杂程度远比后者低。加之Bellman-Ford算法能处理各种边值权情况下的最短路径问题,因而还是非常优秀的。

 焊接FORD法兰专用焊条研制
焊接FORD法兰专用焊条研制
焊接FORD法兰专用焊条研制
焊接FORD法兰专用焊条研制——提出了对焊接FORD法兰专用焊条的要求,介绍了研制新焊条的技术途径.通过对法兰制作符合艺流程进行试验,结果表明新研制焊条XFS016各项性能优良,达到了预期目的.经对法兰接口实际焊接,其x射线探伤为I级合格.
 焊接FORD法兰专用焊条研制
焊接FORD法兰专用焊条研制
焊接FORD法兰专用焊条研制
提出了对焊接FORD法兰专用焊条的要求,介绍了研制新焊条的技术途径.通过对法兰制作各工艺流程进行试验,结果表明,新研制焊条XE5016各项性能优良,达到了预期目的.经对法兰接口实际焊接,其X射线探伤为Ⅰ级合格.
旋转门算法除了平行四边形算法之外,还能用三角形算法来表示。
图遍历算法
图遍历算法是最基本的图算法之一,由指定节点开始,按照一定规则遍历图结构中所有的连通节点,包括宽度优先搜索(Breadth First Search,BFS)和深度优先搜索(Depth First Search, DFS)等核心算法。
作为最基本的图遍历算法,宽度优先搜索算法代表了图遍历算法的计算特性,具有非常重要的研究意义。一方面,BFS算法是最短路径、邻接查询、可达性查询等算法的实现基础,广泛应用于图分割、信念传播统计以及网络社区结构发现等领域;另一方面,BFS算法作为典型的数据密集型算法,体现了数据密集型应用对高性能计算系统的需求,广泛应用于大规模并行计算系统的数据处理能力评测,已经成为Parboil, Rodinia和Graph500等基准测试程序的核心算法。
在实际应用中,图的规模在不断增大,相应的,对图的存储和处理开销不断增加,有效地实现大规模并行BFS算法具有十分重要的意义。
稀疏线性方程组求解法
稀疏线性方程组的求解是对自然科学和社会科学中许多实际问题进行数值模拟时的关键技术之一。在高层建筑、桥梁、水坝、防洪堤的结构设计中,需对变形与应力情况进行模拟;在油气资源探测与分析、数值天气预报、飞行器的动力学分析中,需利用流体力学方程组进行模拟;在进行恒星大气分析与核爆实验时,常需利用辐射流体力学与粒子统计平衡等规律进行模拟。在对这些问题进行分析模拟时,通常利用偏微分方程建立数学模型。在对偏微分方程的离散求解过程中,稀疏线性方程组求解算法扮演着十分重要的角色。在许多不以偏微分方程建模的问题中,稀疏线性方程组求解同样发挥了重要的作用。在空中交通控制、电力线路中的最优电流问题中,需利用数学规划求解;在对采纳某项政策时在某给定条件下对国内、国际多个区域的相应经济指标进行预测时,需利用CGE模型进行分析;在可靠性分析、排队网络分析与计算机系统性能评估中,常利用具有大量状态的离散Markov链进行模拟。在这些问题的求解中,稀疏线性方程组的求解都占有重要位置,并且往往是整个计算过程中的性能瓶颈,稀疏线性方程组的高效求解是计算数学和工程应用中十分重要的课题之一。
解稀疏线性方程组的方法包括直接法(direct method)与迭代(iterative method)两类。直接法指在不考虑计算舍入误差的情况下,通过包括矩阵分解和三角方程组求解等有限步的操作求得方程组的精确解,因此又称精确法;迭代法指给定一个初始解向量,通过一定的计算构造一个向量列(一般通过逐次迭代得到一系列逼近精确值的近似解),向量列的极限为方程组理论上的精确解。迭代法对存储空间的需求低,在求解高阶非病态稀疏线性方程组方面具有一定优势。然而,迭代法不适合求解病态问题,性能因问题而异,并且面临精度控制、收敛速度慢或不收敛等问题。与迭代法相比,直接法的通用性好,求解结果精度高,性能稳定。当矩阵分解结果能够被多次后续计算重用以及多右端项时,直接法的优势尤其明显。在有限元分析、模拟电路瞬态仿真等应用领域的商用软件均采用直接法求解器作为标准的稀疏线性方程组求解器。但直接法的缺点在于对存储资源要求较高,无法处理高阶稀疏矩阵。
一般来说,迭代法的求解速度高于直接法。但是,如果使用直接法时矩阵分解过程能够被很多后续计算重复使用,则后续的三角阵求解可以非常快速实现,此时直接法在性能上具有优势。典型例子是模拟电路瞬态仿真,这时需要多次以Newton-Raphson方法求解非线性方程,每一次求解均会在工作点附近展开为线性方程,而且所有线性方程的矩阵分解方式都是固定的,因此求解该类问题最好的方法是直接法。稀疏矩阵的矩阵分解在GPU上的实现是很困难的,主要难点在于现有算法的数据依赖性导致可利用的并行性不足。此外,矩阵元素的排列顺序对计算过程中间结果矩阵的非零元素个数有很大影响,同时矩阵分解后的非零元素的分布与原来矩阵可能很不相同。
迭代法的理论基础相对复杂,并且具有多种不同的具体算法,但其基本形式均为从一个猜测解出发,通过多次迭代逐渐收敛,当误差满足一定条件时迭代中止。共扼梯度法(CG)是迭代法的主流方法之一,特别适合于特征值为良态分布的对称正定方程组;其它迭代法包括Jacobi、逐次超松弛(SOR)、广义极小剩余(GMRES)、预条件共扼梯度(PCG)等。迭代法的核心算法是稀疏矩阵向量乘(SpMV),因此实现SpMV的高效并行结构也是实现迭代法的基础。
直接法由高斯消元法发展向来,求解过程包括矩阵排序(matrix ordering)符号分解(symbolic factorization)、数值分解(numerical factorization)、三角方程组求解((triangular solves)四个步骤。其中,矩阵排序和符号分解属于预处理部分。矩阵排序通过启发算法置换稀疏矩阵的行列,试图在后续计算中维持矩阵的稀疏性或数值稳定性。符号分解则是预先对矩阵分解后的稀疏结构进行预测,预先分配存储空间并记录数据相关性。直接法的计算瓶颈在于数值分解部分和三角方程组求解部分,高效的直接法求解依赖于二者的高效实现。
对于一个稀疏线性方程组是选择直接法还是迭代法求解,一般有如下原则:对于低阶矩阵或大型带状矩阵所对应的线性方程组,用直接法求解;而对于大型(非带形)矩阵所对应的线性方程组,用迭代方法求解。实际上,选用何种方法还要看具体的应用背景,比如,对于线性规划和一些结构工程应用,只有直接法是切实可行的。对于精度要求很高的问题,还可以采用由直接法得到初始解再用迭代法进行迭代的方法求解,这种方法称为迭代精化法。
DFSA算法可采用各种方法预测待识别的标签数量,然后动态调整最优帧长,与FSA相比,系统效率有明显改善,接近36.8%。但是,当标签数量较多(特别是标签数量大于500)时,采用由预测标签数量设置最优帧长的方案会使系统效率急剧下降。因此,在标签数量较多的情况下,为了使系统效率得到提高,EPCClass1Gen2标准中采用了Q值算法,该算法可以实时自适应地调整帧长 。
Q值算法
在Q值算法中,阅读器首先发送Query命令,该命令中含有一个参数Q(取值范围0~15),接收到命令的标签可在[0,2Q-1]范围内(称为帧长)随机选择时隙,并将选择的值存入标签的时隙计数器中,只有计数器为0的标签才能响应,其余标签保持沉默状态。当标签接收到阅读器发送的QueryRep命令时,将其时隙计数器减1,若减为0,则给阅读器发送一个应答信号。标签被成功识别后,退出这轮盘存。当有两个以上标签的计数器都为0时,它们会同时对阅读器进行应答,造成碰撞。阅读器检测到碰撞后,发出指令将产生碰撞的标签时隙计数器设为最大值(2Q-1),继续留在这一轮盘存周期中,系统继续盘存直到所有标签都被查询过,然后阅读器发送重置命令,使碰撞过的标签生成新的随机数 。
根据上一轮识别的情况,阅读器发送Query-Adjust命令来调整Q的值,当标签接收到Query-Adjust命令时,先更新Q值,然后在[0,2Q-1]范围内选择随机值。EPCClass1Gen2标准中提供了一种参考算法来确定Q值的范围.其中:Qfp为浮点数,其初值一般设为4.0,对Qfp四舍五入取整后得到的值即为Q;C为调整步长,其典型取值范围是0.1 该算法在参数C的辅助下对Q值进行动态调整,但是C太大会造成Q值变化过于频繁,导致帧长调整过于频繁,C太小又不能快速地实现最优帧长的选择。因此,研究者们对Q值的调整进行了各种优化 。 基于最大吞吐量调整Q值的算法 文献提出一种基于最大吞吐量对Q值进行调整的算法,其中定义了以下变量:Nt为已识别的标签个数;N为识别标签所需的总时隙数;NC为冲突时隙的个数;nu为上一轮未识别的标签个数;e为冲突时隙中的平均标签个数;PC为冲突时隙所占的比例 。 这些参数之间的关系为PC=NC/N,e=nu/Nc,吞吐量=Nt/N。由于Aloha类算法的最大吞吐量为0.368(e-1)[5],该算法以此作为调整Q值的依据。当系统吞吐量达到或接近0.368时,阅读器仅需调用2Q-1次QueryRep命令,而不需要在接下来的盘存周期中调整Q值。当吞吐量小于0.368时,根据未识别的标签个数nu来调整Q值 . 基于分组的位隙Aloha算法 文献提出一种基于分组的位隙Aloha算法,该算法采用位隙Aloha算法中的128位预定序列,代表128个位隙。若某个标签选择了第i个位隙,则将第i位置1,其余各位都置0。当标签数量为15时,位隙Aloha算法可获得最大吞吐率88.38%,但随着标签数量的增加,算法性能急剧下降 。 因此,基于分组的位隙Aloha算法通过对标签进行分组来提高算法的性能。该算法在查询命令中设置了一个位隙计数器的参数Q(Q为整数,且0≤Q≤15),当标签收到阅读器发送的查询命令后,在[0,2Q-1]范围内生成一个随机数,即代表选择了相应的位隙,只有选择了0的标签才会立即响应。同时,该算法根据冲突位隙数动态地对Q值进行调整:当冲突位隙数小于11时,Q减1且最小为0;当冲突位隙数在11~20之间时,Q保持不变;当冲突位隙数大于20时,Q加1且最大不超过15 。 综上所述,基于Aloha的防碰撞算法原理简单、容易实现,对新到达的标签具有较好的适应性,尤其对于标签持续到达的情况有较好的解决方案,但该类算法存在几个明显的缺点:①响应时间不确定,即同一批标签在不同时刻进行识别所需要消耗的时间相差很大;②个别标签可能永远无法被识别;③Aloha算法达到最佳吞吐率的条件是其帧长等于标签数量,当需要识别的标签数量较多或选择的帧长与实际待识别标签数量不符时,系统性能将明显下降。而基于树的算法则很好地解决了这些问题 。