概率论安全分析文献

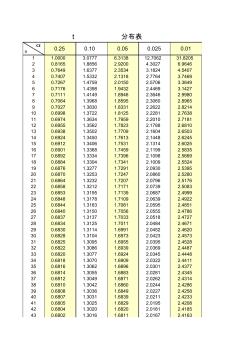 概率论t分布表
概率论t分布表
概率论t分布表
α n 0.25 0.10 0.05 0.025 0.01 1 1.0000 3.0777 6.3138 12.7062 31.8205 2 0.8165 1.8856 2.9200 4.3027 6.9646 3 0.7649 1.6377 2.3534 3.1824 4.5407 4 0.7407 1.5332 2.1318 2.7764 3.7469 5 0.7267 1.4759 2.0150 2.5706 3.3649 6 0.7176 1.4398 1.9432 2.4469 3.1427 7 0.7111 1.4149 1.8946 2.3646 2.9980 8 0.7064 1.3968 1.8595 2.3060 2.8965 9 0.7027 1.3830 1.8331 2.2622 2.8214 10 0.6998 1.3722 1.8125 2.2281 2.7
 第2章概率论.
第2章概率论.
第2章概率论.
第 2章 习题同步解析 1. 下列给出的两个数列,是否为随机变量的分布律,并说明理由. (1) 5,4,3,2,1,0, 15 i i pi ;(2) 3,2,1,0, 6 5 2 i i pi ;(3) 5,4,3,2,1, 25 1 i i p i 解 要说明题中给出的数列,是否是随机变量的分布律,只要验证 ip 是否满足下列两个条 件:① ,2,1,0 ipi ,② 1 i ip . 依据上面的说明可得( 1)中的数列为随机变量的分布律; ( 2)中的数列不是随机变量 的分布律,因为 0 6 4 6 95 3p ;(3)中的数列不是随机变量的分布律,这是因为 5 1 1 25 20 i ip . 2. 一袋中有 5 个乒乓球,编号分别为 1,2,3,4, 5,从中随机地取 3 个,以 X 表 示取出的 3个球中最大号码,求 X 的概率分布. 解 依题意 X 可能取到的值为 3, 4,