加法器基本方法文献

 16位加法器设计
16位加法器设计
16位加法器设计
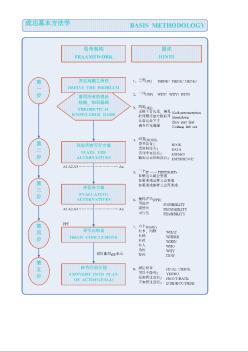
计算机组成原理 课 程 设 计 报 告 题目 16 位加法器设计 B 院系 信息科学技术学院 专业 计算机科学与技术 班级 11 计本( 2) 教师 学生 学号 2 内容提要 本设计在其他基本加法器的基础上改进为超前进位加法器, 它避免了串行进 位加法器的进位延迟,提高了速度。其主要分为四章,第一章为设计概述,主要 介绍设计的任务、目标,以及设计环境,第二章为总体设计方案,其主要介绍本 设计中系统设计的框架。 第三章为仿真测试, 给出了系统在仿真环境下波形测试 结果,看是否满足题目要求。第四章为设计心得总结,主要是介绍在经过本次设 计后,自己的一些心得体会。最后还给出了本设计的一些参考文献。 3 前言 计算机组成原理是一门实践性很强的课程; 其课程设计目的在于综合运用所 学知识,全面掌握微型计算机及其接口的工作原理