
HDFS是什么?
HDFS 全称 Hadoop Distributed File System ,简称HDFS,是一个分布式文件系统。它是谷歌的GFS提出之后出现的另外一种文件系统。它有一定高度的容错性,而且提供了高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS 提供了一个高度容错性和高吞吐量的海量数据存储解决方案。
优点
1、存储超大文件
2、标准流式访问:“一次写入,多次读取”
3、运行在廉价的商用机器集群上
不足
1、不能满足低延迟的数据访问
2、无法高效存储大量小文件
3、暂时不支持多用户写入及随意修改文件
HDFS概念理解
hdfs架构图如下:

1、文件块(图中1、2、3、4带颜色的小正方形)
文件分成块存储(默认64M,如今版本是128是M),多台计算机存储。DateNode中存储以数字编号的方块(见上图)用于备份,每个块都会复制到几台机器上(默认3台),如果一个块不可用,可从其它地方读取副本。副本是3,表示一共3处有该块。如果配置文件中副本设置为 4 ,但是结果只有2台datanode,最后副本还是2
1000个1M的小文件会占用1024个块和1024个 inode,但是他只是占用1个块中的1M,不会占用整个空间,不过由于inode存储在NameNode的内存里,如果NameNode内存不足以存储inode,那么就不能再存储文件了、所以说HDFS并不适合存储小文件,有时候还要将小文件合并为大文件。
显示块信息命令:
hdfs fsck / -files –blocks //列出根目录下各个文件由哪些块存储。
//它只是从NameNode获取信息,不与DateNode交互。
2、 NameNode和DataNode
NameNode(名字节点): 管理文件系统命名空间;维护文件系统树内所有文件和目录,记录每个文件在哪个DateNode的位置和副本信息,协调客户端对文件的访问。 以两种文件格式存在:
fsimage_*:元数据镜像文件,即系统的目录树,包括文件目录和inodes元信息(文件名,文件大小,创建时间,备份级别,访问权限,block的size,所有block的构成),每个inode是hdfs的一个代表文件或者目录的元数据。这个镜像文件相当于hdfs的元数据额数据库文件。
edits_*:编辑日志文件,也就是事务日志文件,也就是针对文件系统做的修改操作记录,记录元数据的变化,相当于操作日志文件。一个文件的创建,追加,移动等。 NameNode内存中存储的是=fsimage+edits 检查点:NameNode启动时,从磁盘中读取上面两种文件,然后把edits_*里面记录的事务全部刷新到 fsimage_*中,这样就截去了旧的edits_*事务日志,这个过程叫checkpoint。
上面文件在~/hadoop-2.6/dfs/name/current目录下(在hdfs-site.xml) ,除此之外,还有VERSION(版本信息,包含文件系统唯一标识符)和seen_txid(事务管理,里面保存一个整数,表示edits_*的尾数)两个文件。
DataNode(数据节点):存储,检索数据块。定期向NameNode发送所存储的块的列表。存储的块大小是64M,并且尽量把数据块分布不同的DateNode节点上。
上图某文件被分成4块,在多个DataNode中存储,而且每块都复制两个备份,存储在其它DataNode中。这些数据的存储目录/home/hduser/hadoop-2.6/dfs/data(dfs-site.xml中指定)。例如下面文件:/home/hduser/hadoop-2.6/dfs/data/current/BP-1111-ip-2222/current/finalized/subbdir0/sudir0,该目录下的文件包括blk_{id}和blk_{id}.meta,前者是二进制格式的数据块,后者是数据块的元信息(版本信息,类型信息 )
DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据的创建,删除和复制工作。如果NameNode数据损坏,HDFS所有文件都不能访问,为了保证高可用性,Hadoop对NameNode进行了补充,即Sencondary NameNode。
3、 Secondary NameNode结点
系统同步运行一个Secondary NameNode,也称二级NameNode,周期的备份NameNode,它可以用来恢复NameNode。由于有一定的滞后,所以会带来数据的损失。为了防止宕机,一般我们会把它放在另外一台计算机。使用hdfs-site.xml中dfs.namenode.secondary.http-address属性可以通过浏览器查看Secondary NameNode的运行状态。 默认是1小时,从NameNode获取fsimage和edits进行合并,然后再发送给namenode,减少namenode的工作量。

HDFS体系架构
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。 一次写,多次读取:一个文件一旦创建,写入,关闭之后就不需要修改了。
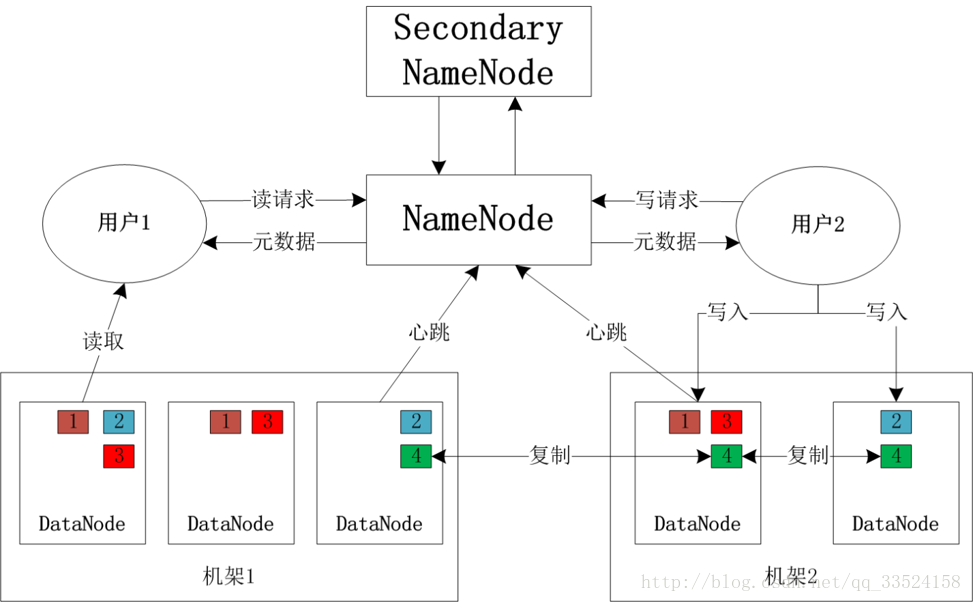
读写流程如下: 读流程:客户端向NameNode请求访问某个文件,NameNode返回该文件位置在哪个DataNode上,然后客户端从DataNode上读取数据。 写流程:客户端向NameNode发出写文件写请求,NameNode告诉客户端向哪个DataNode写文件,然后客户端将文件写入该DataNode节点,随后该 DataNode将该文件自动复制到其它DataNode节点上,默认三份备份。
HDFS常见节点管理:1 节点添加 可扩展性是一个重要特征,往HDFS集群中添加一个节点步骤如下:
1) 对新节点进行系统配置(hostname,hosts,jdk,防火墙等)
2) 对新节点进行hadoop的安装和配置,和其它DataNode一样。
3) 在NameNode中修改~/hadoop-2.6/etc/hadoop/Slaves文件,加入新节点名称。
4) 启动(start-all.sh,或者start-dfs.sh,start-yarn.sh)
2 负载均衡 HDFS的数据在各个DataNode中的分布可能不均匀,尤其是DataNode出现故障或者新增节点时,采用下面命令可以重新平衡DataNode的数据块分布: $start-balancer.sh
3 安全机制 由于NameNode统一调度,没有它文件系统无法使用,采用下面两种机制确保其安全:
1) 把NameNode存储的元数据转移到其它文件系统上。
2) 使用Secondary NameNode同步备份。
加米谷大数据是一家专注于大数据培训的机构,提供个人培训和企业内训;如果您是0基础学习大数据或者转行大数据行业,欢迎实地了解考察!




