---
有同学反映,我们视频一上来就讲干货,希望适当普及一下相关概念,这篇就是。
ARM处理器解析
ARM9、ARM11是哈佛5级流水线结构,所以性能要高一点。ARM9和ARM11大多带内存管理器,跑操作系统好一点,ARM7适合裸奔。我们惯称的 ARM9系列中又存在ARM9与ARM9E两个系列,其中ARM9 属于ARM v4T架构,典型处理器如ARM9TDMI和ARM922T;
而ARM9E属于ARM v5TE架构,典型处理器如ARM926EJ和ARM946E。因为后者的芯片数量和应用更为广泛,所以我们提到ARM9的时候更多地是特指ARM9E系列处理器(主要就是ARM926EJ和ARM946E这两款处理器)。
下面关于ARM9的介绍也是更多地集中于ARM9E。
2
ARM7处理器和ARM9E处理器的流水线差别
对嵌入式系统设计者来说,硬件通常是第一考虑的因素。针对处理器来说,流水线则是硬件差别的最明显标志,不同的流水线设计会产生一系列硬件差异。
让我们来比较一下ARM7和ARM9E的流水线,ARM9E从ARM7的3级流水线增加到了5级,ARM9E的流水线中容纳了更多的逻辑操作,但是每一级的逻辑操作却变得更为简单。
比如原来 ARM7的第三级流水,需要先内部读取寄存器、然后进行相关的逻辑和算术运算,接着处理结果回写,完成的动作非常复杂;
而在ARM9E的5级流水中,寄存器读取、逻辑运算、结果回写分散在不同的流水当中,使得每一级流水处理的动作非常简洁。这就使得处理器的主频可以大幅度地提高。因为每一级流水都对应 CPU的一个时钟周期,如果一级流水中的逻辑过于复杂,使得执行时间居高不下,必然导致所需的时钟周期变长,造成CPU的主频不能提升。所以流水线的拉长,有利于CPU主频的提高。
在常用的芯片生产工艺下,ARM7一般运行在100MHz左右,而ARM9E则至少在200MHz以上。
3
ARM9E处理器的存储器子系统
像ARM926EJ 和ARM946E这两个最常见的ARM9E处理器中,都带有一套存储器子系统,以提高系统性能和支持大型操作系统。如图2所示,一个存储器子系统包含一个 MMU(存储器管理单元)或MPU(存储器保护单元)、高速缓存(Cache)和写缓冲(Write Buffer);CPU通过该子系统与系统存储器系统相连。
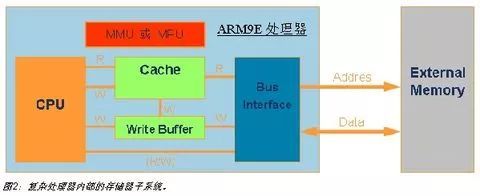
高速缓存和写缓存的引入是基于如下事实,即处理器速度远远高于存储器访问速度;如果存储器访问成为系统性能的瓶颈,则处理器再快也是浪费,因为处理器需要耗费大量的时间在等待存储器上面。
高速缓存正是用来解决这个问题,它可以存储最近常用的代码和数据,以最快的速度提供给CPU处理(CPU访问Cache不需要等待)。
4
复杂处理器内部的存储器子系统
MMU则是用来支持存储器管理的硬件单元,满足现代平台操作系统内存管理的需要;它主要包括两个功能:一是支持虚拟/物理地址映射,二是提供不同存储器地址空间的保护机制。
一个简单的例子可以帮助我们理解MMU的功能,在一个操作系统下,程序开发人员都是在操作系统给定的API和编程模型下开发程序;操作系统通常只开放一个确定的存储器地址空间给用户。这样就带来 一个直接的问题,所有的应用程序都使用了相同的存储器地址空间,如果这些程序同时启动的话(在现在的多任务系统中这是非常常见的),就会产生存储器访问冲 突。那操作系统是如何来避免这个问题的呢?
操作系统会利用MMU硬件单元完成存储器访问虚拟地址到物理地址的转换。所谓虚拟地址就是程序员在程序中使用的逻辑地址,而物理地址则是真实存储器单元的空间地址。MMU通过一定的规则, 可以把相同的虚拟地址映射到不同的物理地址上去。这样,即使有多个使用相同虚拟地址的程序进程启动,也可以通过MMU调度把它们映射到不同的物理地址上 去,不会造成系统错误。
5
MMU的功能和作用
MMU 处理地址映射功能之外,还能给不同的地址空间设置不同的访问属性。比如操作系统把自己的内核程序地址空间设置为用户模式下不可访问,这样的话用户应用程序就无法访问到该空间,从而保证操作系统内核的安全性。
MPU与MMU的区别在于它只有给地址空间设置访问属性的功能而没有地址映射功能。Cache以及MMU等硬件单元的引入,给系统程序员的编程模型带来了许多全新的变化。
除了需要掌握基本的概念和使用方法之外,下面几个针对系统优化的点既有趣又重要:
1.系统实时性考虑因素
为保存地址映射规则的页表(Page Table)非常庞大,通常MMU中只是存储器了常用的一小段页表内容,大部分页表内容都存储于主存储器里面;当调用新的地址映射规则时,MMU可能需要读取主存储器来更新页表。
这在某些情况下会造成系统实时性的丢失。比如当需要执行一段关键的程序代码时,如果不巧这段代码使用的地址空间不在当前MMU的页表处理范围里面,则MMU首先需要更新页表,然后完成地址映射,接着才能相应存储器访问;
整个地址译码过程非常长,给实时性带来非常大的不利影响。所以一般来说带MMU和Cache的系统在实时性上不如一些简单的处理器;不过也有一些办法能够帮助提高这些系统的实时效率。
一个简单的办法是在需要的时候关闭MMU和Cache,这样就变成一个简单处理器了,可以马上提高系统实时性。当然很多情况下这不可行;
在ARM的MMU和 Cache设计中,有一个锁定的功能,就是说你可以指定某一块页表在MMU中不会被更新掉,某一段代码或数据可以在Cache中锁定而不会被刷新掉;程序员可以利用这个功能来支持那些实时性要求最高的代码,保证这些代码始终能够得到最快的响应和支持。
2.系统软件优化
在嵌入式系统开发中,很多系统软件优化的方法都是相同和通用的,多数情况下这种规则也适用于ARM9E架构上。如果你已经是一个ARM7的编程高手,那么恭喜你,以前你掌握的优化方法完全可以用在新的ARM9E平台上,但是会有一些新的特性需要你加倍注意。最重要的便是Cache的作用,Cache本身并不 带来编程模型和接口的变化,但是如果我们考察Cache的行为,就能够发现对于软件优化,Cache是有比较大的影响的。
Cache在物理上就是一块高速SRAM,ARM9E的Cache组织宽度(cache line)都是4个word(也就是32个字节);Cache的行为受系统控制器控制而不是程序员,系统控制器会把最近访问存储器地址附近的内容复制到Cache中去,这样,当CPU访问下一个存储器单元的时候(这个访问既可能是取指,也可能是数据),可能这个存储器单元的内容已经在Cache里了,所以CPU不需要真的到主存储器上去读取内容,而直接读取Cache高速缓存上面的内容就可以了,从而加快了访问的速度。
从Cache的工作原理我们可以看 到,其实Cache的调度是基于概率的,CPU要访问的数据既可能在Cache中已经存在(Cache hit),也可能没有存在(Cache miss)。在Cache miss的情况下,CPU访问存储器的速度会比没有Cache的情况更坏,因为CPU除了要从存储器访问数据以外,还需要处理Cache hit或miss的判断,以及Cache内容的刷新等动作。
只有当Cache hit带来的好处超过Cache miss带来的牺牲的时候,系统的整体性能才能得到提高,所以Cache的命中率成为一个非常重要的优化指标。
根据Cache行为的特点,我们可以直观地得到提高Cache命中率的一些方法,如尽可能把功能相关的代码和数据放置在一起,减少跳转次数;跳转经常会引起 Cache miss。保持合适的函数大小,不要书写太多过小的函数体,因为线性的程序执行流程是最为Cache友好的。
循环体最好放置在4个word对齐的地址,这 样就能保证循环体在Cache中是行对齐的,并且占用最少的Cache行数,使得被多次调用的循环体得到更好的执行效率。
6
性能和效率的提升
前面介绍了ARM9E相比于ARM7性能上的提高,这不仅表现在ARM9E有更快的主频、更多的硬件特性上面,还体现在某些指令的执行效率上面。执行效率我 们可以用CPU的时钟周期数(Cycle)来衡量;
运行同一段程序,ARM9E的处理器可以比ARM7节省大约30%左右的时钟周期。
效率的提高主要来自于ARM9E对于Load-Store指令执行效率的增强。我们知道在RISC架构的处理器中,程序中大约有30%的指令是Load- Store指令,这些指令的效率对系统效率的贡献是最明显的。
ARM9E中有两个因素帮助提高Load-Store指令的效率:
1)ARM9内核是哈佛架构,拥有独立的指令和数据总线;相对应,ARM7内核的指令和数据总线复用的冯诺依曼架构。
2)ARM9的5级流水线设计把存储器访问和寄存器写回放在不同的流水上面。
两者结合,使得在指令流的执行过程中每个CPU时钟周期都可以完成一个Load或Store指令。
下面的表格比较了ARM7和ARM9处理器之间的Load -Store指令。
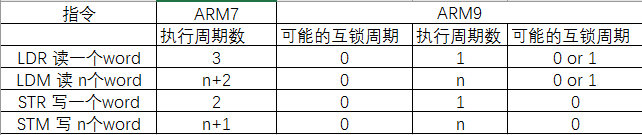
从中可以看出所有的Store指令ARM9比ARM7省1个周期,Load指令可以省2个周期(在没有互锁的情况下,编译工具能够通过 编译优化消除大多数的互锁可能)。
综合各种因素,ARM9E处理器拥有非常强大的性能。但是在实际的系统设计中,设计人员并不总是把处理器性能开到最大,理想情况是把处理器和系统运行频率降低,使得性能刚好能满足应用需求; 达到节省功耗和成本的目的。
在评估系统能够提供的处理器能力过程中,DMIPS指标被很多人采用; 同时它也被广泛应用于不同处理器间的性能比较。
但是用DMIPS来衡量处理器性能存在很大的缺陷。 DMIPS并非字面上每秒百万条指令的意思,它是一个测量CPU运行一个叫Dhrystone的测试程序时表现出来的相对性能高低的一个单位(很多场合人们也习惯用MIPS作为这个性能指标的单位)。因为基于程序的测试容易受到恶意优化的干扰,并且DMIPS指标值的发布不受任何机构的监督,所以使用DMIPS进行评估时要慎重。
例如对Dhrystone测试程序进行不同的编译处理,在同一个处理器上运行也可以得出差别很大的结果。
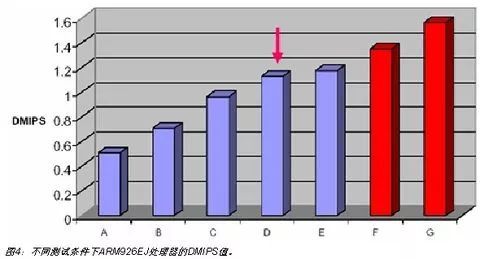
DMIPS另外一个缺点是不能测量处理器的数字信号处理能力和Cache/MMU子系统的性能。因为Dhrystone测试程序不包含DSP表达式,只包含一些整型运算和字符串处理,并且测试程序偏小,几乎可以完整地放在Cache里面运行而无需与外部存储器进行交互。这样就难以反映处理器在一个真实系统中的真正性 能。
一种值得鼓励的评估方法是站在系统的角度看问题,而不仅仅拘泥于CPU本身;而系统性能评估最好的测试向量就是用户应用程序或相近的测试程序,这是用户所需的最真实的结果。
7
ARM9E处理器的DSP运算能力
伴随应用程序的多样化和复杂化,诸如多媒体、音视频功能在嵌入式系统里面也是全面开花。这些应用需要相当的DSP处理能力;如果是在传统的RISC架构上实 现这些算法,所需的资源(频率和存储器等)会非常不经济。
ARM9E处理器一个非常重要的优势就是拥有轻量级的DSP处理能力,以非常小的成本(CPU增 加功能需要增加硬件)换来了非常实用的DSP性能。
因为CPU的DSP能力并不直接反映在像DMIPS这样的评测指标中,同时像以前的ARM7处理器中也没有类似的概念;所以这一点对所有使用ARM9E处理器进行开发的人来说,都是需要注意的一个要点。
ARM9E的DSP扩展指令,主要包括三个类型:
1)单周期的16x16和32x16 MAC操作,因为数字信号处理中甚少32位宽的操作数,在32位寄存器中可以对操作数分段运算显得非常有用。
2)对原有的算术运算指令增加了饱和处理扩展,所谓饱和运算,就是当运算结果大于一个上限或小于一个下限时,结果就等于上限或是下限;
饱和处理在音频数据和视频像素处理中普遍使用,现在一条单周期饱和运算指令就能够完成普通RISC指令“运算-判断-取值”这一系列操作。
3)前导零(CLZ)运算指令,提高了归一化和浮点运算以及除法操作的性能。
以流行的MP3解码程序为例。整个解码过程中前端的三个步骤是运算量最大的,包括比特流的读入(解包)、霍夫曼译码还有反量化采样(逆变换)。
ARM9E的 DSP指令正好可以高效地完成这些运算。以44.1 KHz@128 kbps码率的MP3音乐文件为例,ARM7TDMI需要占用20MHz以上的资源,
而ARM926EJ则只要小于10MHz的资源在从ARM7到ARM9的平台转变过程中,有一件事情是非常值得庆幸的,即ARM9E能够完全地向后兼容ARM7上的软件;并且开发人员面对的编程模型和架构基础也保持一致。
但是毕竟ARM9E中增加了很多新的特性,为了充分利用这些新的资源,把系统性能优化好,需要我们对ARM9E做更多深入地了解。
---end--


6月中旬来了,有同学询问我们的淘宝店铺是否搞降价活动,这里统一回复:产品定价已经很亲民,我们不打价格战,和往年一样,不参加618大促,目前只有现金奖励活动(点击下面标题了解详情):
【有奖活动】完成课后作业:裸机测试界面, 赢取奖金2000元人民币,
按要求完成最高可获得2000元现金奖励~,适合时间充裕还可以赚外快补贴生活费的在校生,何乐而不为?
41人加群,据小编了解目前已有好几个人正在写代码...你还在等什么?
免责声明:本文系网络转载,有改动,版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将根据您提供的版权证明材料确认版权并支付稿酬或者删除内容。

 基于ARM微控制器的金卤灯用电子镇流器
基于ARM微控制器的金卤灯用电子镇流器