选择特殊符号
选择搜索类型
请输入搜索
在自动编码器AutoEncoder的基础上加上L1的正则限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源),我们就可以得到Sparse AutoEncoder法。
如图三,其实就是限制每次得到的表达code尽量稀疏。因为稀疏的表达往往比其他的表达要有效(人脑好像也是这样的,某个输入只是刺激某些神经元,其他的大部分的神经元是受到抑制的)
对于没有带类别标签的数据,由于为其增加类别标记是一个非常麻烦的过程,因此我们希望机器能够自己学习到样本中的一些重要特征。通过对隐藏层施加一些限制,能够使得它在恶劣的环境下学习到能最好表达样本的特征,并能有效地对样本进行降维。这种限制可以是对隐藏层稀疏性的限制。
如果给定一个神经网络,我们假设其输出与输入是相同的,然后训练调整其参数,得到每一层中的权重。自然地,我们就得到了输入的几种不同表示(每一层代表一种表示),这些表示就是特征。自动编码器就是一种尽可能复现输入信号的神经网络。为了实现这种复现,自动编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。
当然,我们还可以继续加上一些约束条件得到新的Deep Learning方法,如:如果在AutoEncoder的基础上加上L1的Regularity限制(L1主要是约束隐含层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源),我们就可以得到Sparse AutoEncoder法。
之所以要将隐含层稀疏化,是由于,如果隐藏神经元的数量较大(可能比输入像素的个数还要多),不稀疏化我们无法得到输入的压缩表示。具体来说,如果我们给隐藏神经元加入稀疏性限制,那么自编码神经网络即使在隐藏神经元数量较多的情况下仍然可以发现输入数据中一些有趣的结构。
自编码器最初提出是基于降维的思想,但是当隐层节点比输入节点多时,自编码器就会失去自动学习样本特征的能力,此时就需要对隐层节点进行一定的约束,与降噪自编码器的出发点一样,高维而稀疏的表达是好的,因此提出对隐层节点进行一些稀疏性的限值。稀疏自编码器就是在传统自编码器的基础上通过增加一些稀疏性约束得到的。这个稀疏性是针对自编码器的隐层神经元而言的,通过对隐层神经元的大部分输出进行抑制使网络达到一个稀疏的效果。
分辨率1000P/R,开路输出。
PG是脉冲发生器(Pulse Generator)的缩写PG的功能的是产生脉冲信号,信号主要含两方面信息1,检测转子的磁极位置,并根据该位置通入电流2,检测机械的位置和速度
每台编码器的规格指标中,都有标明 分辨率是多少。 单位是 线/圈; 假设是 1024线/圈,那么就意味着 编码器每转一圈,就将送出1024个A相和1024个B相的脉冲。 这时就看你的脉...
假设我们只有一个没有带类别标签的训练样本集合
自编码神经网络尝试学习一个
我们刚才的论述是基于隐藏神经元数量较小的假设。但是即使隐藏神经元的数量较大(可能比输入像素的个数还要多),我们仍然通过给自编码神经网络施加一些其他的限制条件来发现输入数据中的结构。具体来说,如果我们给隐藏神经元加入稀疏性限制,那么自编码神经网络即使在隐藏神经元数量较多的情况下仍然可以发现输入数据中一些有趣的结构。
稀疏性可以被简单地解释如下。如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。这里我们假设的神经元的激活函数是sigmoid函数。如果你使用tanh作为激活函数的话,当神经元输出为-1的时候,我们认为神经元是被抑制的。
注意到
进一步,让
表示隐藏神经元
其中,
为了实现这一限制,我们将会在我们的优化目标函数中加入一个额外的惩罚因子,而这一惩罚因子将惩罚那些
这里,
其中
这一惩罚因子有如下性质,当
我们可以看出,相对熵在
我们的总体代价函数可以表示为
其中
为了对相对熵进行导数计算,我们可以使用一个易于实现的技巧,这只需要在你的程序中稍作改动即可。具体来说,前面在后向传播算法中计算第二层(
我们将其换成
就可以了。
有一个需要注意的地方就是我们需要知道
证明上面算法能达到梯度下降效果的完整推导过程不再本教程的范围之内。不过如果你想要使用经过以上修改的后向传播来实现自编码神经网络,那么你就会对目标函数
稀疏性可以被简单地解释如下。如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。这里我们假设的神经元的激活函数是sigmoid函数。如果你使用tanh作为激活函数的话,当神经元输出为-1的时候,我们认为神经元是被抑制的。
input_nodes=8*8//输入节点数 hidden_size=100//隐藏节点数 output_nodes=8*8//输出节点数
从mat文件中读取图像块,随机生成10000个8*8的图像块。
defsampleImage():
mat=scipy.io.loadmat('F:/ml/code/IMAGES.mat')
pic=mat['IMAGES']
shape=pic.shape
patchsize=8
numpatches=1000
patches=[]
i=np.random.randint(0,shape[0]-patchsize,numpatches)
j=np.random.randint(0,shape[1]-patchsize,numpatches)
k=np.random.randint(0,shape[2],numpatches)
forlinrange(numpatches):
temp=pic[i[l]:(i[l] patchsize),j[l]:(j[l] patchsize),k[l]]
temp=temp.reshape(patchsize*patchsize)
patches.append(temp)
returnpatchesdefxvaier_init(input_size,output_size): low=-np.sqrt(6.0/(input_nodes output_nodes)) high=-low returntf.random_uniform((input_size,output_size),low,high,dtype=tf.float32)
代价函数由三部分组成,均方差项,权重衰减项,以及稀疏因子项。
defcomputecost(w,b,x,w1,b1): p=0.1 beta=3 lamda=0.00001 hidden_output=tf.sigmoid(tf.matmul(x,w) b) pj=tf.reduce_mean(hidden_output,0) sparse_cost=tf.reduce_sum(p*tf.log(p/pj) (1-p)*tf.log((1-p)/(1-pj))) output=tf.sigmoid(tf.matmul(hidden_output,w1) b1) regular=lamda*(tf.reduce_sum(w*w) tf.reduce_sum(w1*w1))/2 cross_entropy=tf.reduce_mean(tf.pow(output-x,2))/2 sparse_cost*beta regular# regular sparse_cost*beta returncross_entropy,hidden_output,output
为了使隐藏单元得到最大激励(隐藏单元需要什么样的特征输入),将这些特征输入显示出来。
defshow_image(w):
sum=np.sqrt(np.sum(w**2,0))
changedw=w/sum
a,b=changedw.shape
c=np.sqrt(a*b)
d=int(np.sqrt(a))
e=int(c/d)
buf=1
newimage=-np.ones((buf (d buf)*e,buf (d buf)*e))
k=0
foriinrange(e):
forjinrange(e):
maxvalue=np.amax(changedw[:,k])
if(maxvalue<0):
maxvalue=-maxvalue
newimage[(buf i*(d buf)):(buf i*(d buf) d),(buf j*(d buf)):(buf j*(d buf) d)]=
np.reshape(changedw[:,k],(d,d))/maxvalue
k =1
plt.figure("beauty")
plt.imshow(newimage)
plt.axis('off')
plt.show()通过AdamOptimizer下降误差,调节参数。
defmain():
w=tf.Variable(xvaier_init(input_nodes,hidden_size))
b=tf.Variable(tf.truncated_normal([hidden_size],0.1))
x=tf.placeholder(tf.float32,shape=[None,input_nodes])
w1=tf.Variable(tf.truncated_normal([hidden_size,input_nodes],-0.1,0.1))
b1=tf.Variable(tf.truncated_normal([output_nodes],0.1))
cost,hidden_output,output=computecost(w,b,x,w1,b1)
train_step=tf.train.AdamOptimizer().minimize(cost)
train_x=sampleImage()
sess=tf.Session()
sess.run(tf.global_variables_initializer())
foriinrange(100000):
_,hidden_output_,output_,cost_,w_=sess.run([train_step,hidden_output,output,cost,w],
feed_dict={x:train_x})
ifi00==0:
print(hidden_output_)
print(output_)
print(cost_)
np.save("weights1.npy",w_)
show_image(w_)2100433B
文| Aaqilb Saeed 译| 翟向洋
包括完整代码和数据集的 ipython 笔记本可以从阅读原文链接内获得。
在本教程中,我们会把去噪自编码应用在购物篮(market basket)数据的协同滤波上。学习模型将根据用户购物篮中的商品来推荐相近的商品。
本教程使用的是 groceries 数据集,它包括 9835 次交易(即在购物篮中被一起购买的商品条目)。我们将数据进行训练、测试和验证。图 1 描述了原始数据集,我们需要处理并将其转换为对输入模型可用的格式。为此,每一次交易都将被表示为一个二进制向量,其中 1 表示某个商品在购物篮,否则为 0 。让我们首先读取该数据集并定义几个辅助函数,找出单一的商品条目,将他们转换成 One-hot encoded(一位有效编码的)形式,并从二进制向量转换为商品条目。此外,图 2 提供了 10 项在数据集中最频繁出现的商品条目。





图一: 购物篮数据
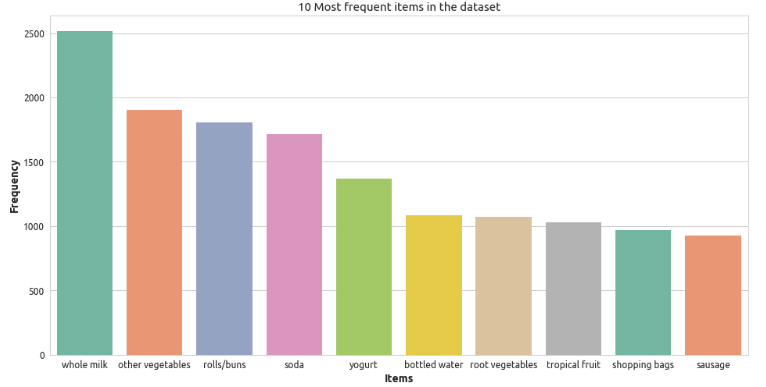
图二:数据集中出现最多的货品
自编码器模型试着(learn)重建它自己的输入。当这样做的时候,它学习(learn)数据的突出表示。因此,它也用来实现降维的目的。该模型由两个组件组成:一个编码器和一个解码器。编码器映射输入-->,解码器从降维重新产生输入,即映射-->。输入中的噪声被引入(例如通过Dropout)到训练集,避免了学习一个恒等函数,由此得名为自编码降噪。在我们的例子中,在模型训练期间,一些缺少某些物品的嘈杂或损坏的购物篮数据将被用作输入。在测试期间,一位有效编码的购物篮的商品条目将被馈入模型以获得商品条目预测。然后从输出,我们必须选择概率比一些阈值更大的商品条目(此例,如果p>=0.1,则为1,否则为0),以转换回一位有效编码向量。最后,在二进制向量中带有1的商品条目将被推荐给用户。
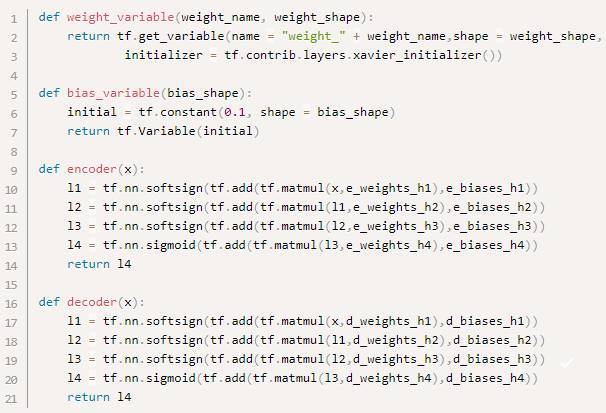
现在让我们定义一个4层自编码降噪模型(例如,4层编码器和4层解码器)。软标记激活函数(the soft sign activation function)用在前三层的编码器和解码器,而sigmoid用在第四层。二进制交叉熵被用作使用随机梯度下降法的变体(通常称为Adam)来最小化的损失函数。模型架构如图2所示,可以看出输入维数为169(即数据集中单一商品条目的数量)。同样,神经元的数量在第一、第二、第三和第四层分别是128、64、32和16。在输入层以0.6的概率引入流失(dropout)(即随机流失40%的输入)。此外,编码器的权重使用频率为0.00001的则正则化。

图三:降噪模型的结构


这里是所有的代码:我们需要定义我们的模型。以下提供的代码会训练/评估自编码器并计算ROC、AUC的分数。

以下是该模型提供的一些关于测试集的推荐结果:
购物车中的商品条目:火腿、草药、洋葱、起泡酒
推荐的商品条目:瓶装水,其他蔬菜,面包(卷),根蔬菜,购物袋,苏打水,热带水果,全脂牛奶,酸奶
购物车中的商品条目:餐巾,香肠,白葡萄酒
推荐的商品条目:其他蔬菜,面包(卷),苏打水,全脂牛奶,酸奶
购物车中的商品条目:磨砂清洁剂,糖果,鸡肉,清洁剂,根蔬菜,香肠,热带水果,全脂牛奶,酸奶
推荐的商品条目:牛肉,瓶装啤酒,瓶装水,棕色面包,黄油,罐装啤酒,柑橘类水果,咖啡,凝乳,国产鸡蛋,法兰克福香肠,水果/蔬菜汁,人造黄油,报纸,其他蔬菜,糕点,水果,猪肉,卷饼/馒头,根蔬菜,香肠,购物袋,苏打水,热带水果,鞭打/酸奶油,酸奶
-END-
译者 | 翟向洋

北京理工大学研究生一枚,吃瓜群众,热爱学习。
后台回复 “志愿者”
了解如何加入我们
译码器是组合逻辑电路的一个重要的器件,其可以分为:变量译码和显示译码两类。
变量译码:一般是一种较少输入变为较多输出的器件,一般分为2n译码和8421BCD码译码两类。
显示译码:主要解决二进制数显示成对应的十、或十六进制数的转换功能,一般其可分为驱动LED和驱动LCD两类。
译码是编码的逆过程,在编码时,每一种二进制代码,都赋予了特定的含义,即都表示了一个确定的信号或者对象。把代码状态的特定含义"翻译"出来的过程叫做译码,实现译码操作的电路称为译码器。或者说,译码器是可以将输入二进制代码的状态翻译成输出信号,以表示其原来含义的电路。
根据需要,输出信号可以是脉冲,也可以是高电平或者低电平。
译码器的种类很多,但它们的工作原理和分析设计方法大同小异,其中二进制译码器、二-十进制译码器和显示译码器是三种最典型,使用十分广泛的译码电路。
二进制码译码器,也称最小项译码器,N中取一译码器,最小项译码器一般是将二进制码译为十进制码;
代码转换译码器,是从一种编码转换为另一种编码;
显示译码器,一般是将一种编码译成十进制码或特定的编码,并通过显示器件将译码器的状态显示出来。


