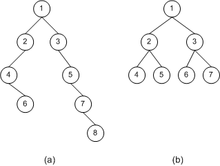
用C语言最简单的哈夫曼算法实现
#include <stdio.h>
#include <conio.h>
struct BinaryTree
{
long data;
int lchild,rchild;
};
//定义一个二叉树结构
void sort(struct BinaryTree cc[],int l,int r);
void xx(long kk,struct BinaryTree cc[]);
void zx(long kk,struct BinaryTree cc[]);
void hx(long kk,struct BinaryTree cc[]);
//对函数的声明
main(void)
{
struct BinaryTree Woods[101];
long i,j,n,xs,k;
scanf("%d",&n);
for ( i=1; i<=n; ++i)
{
scanf("%d",&Woods.data);
Woods.lchild=0;
Woods.rchild=0;
} //依次读入权值
k=n;
xs=1;
--n;
while (k>1)
{
sort(Woods,xs,n+1);
Woods[n+2].data=Woods[xs].data+Woods[xs+1].data; //将根结点权值为左子树也右子树权值之和
Woods[n+2].lchild=xs; //对左子树和右子树的设置
Woods[n+2].rchild=xs+1;
++n;
xs=xs+2;
--k;
} //哈夫曼算法
printf("%s","preorder:");
xx(n+1,Woods);
printf("\n%s","inorder:");
zx(n+1,Woods);
printf("\n%s","postorder");
hx(n+1,Woods);
printf("\n"); //输出先序,中序,后序序列
getch();
}
//快速排序
void sort(struct BinaryTree cc[],int l,int r)
{
long x,y;
int i,j,rc,lc;
i=l;
j=r;
x=cc[(l+r)/2].data;
if (r<l)
return;
do
{
while(cc.data<x)
++i;
while(x<cc[j].data)
--j;
if (i<j)
{
y=cc.data;
rc=cc.rchild;
lc=cc.lchild;
cc.data=cc[j].data;
cc.lchild=cc[j].lchild;
cc.rchild=cc[j].rchild;
cc[j].data=y;
cc[j].lchild=lc;
cc[j].rchild=rc;
++i;
--j;
}
}
while(i>j);
if (i<r)
sort(cc,i,r);
if (j>l)
sort(cc,l,j);
}
//先序序列
void xx(long kk,struct BinaryTree cc[])
{
if (cc[kk].data!=0)
{
printf("%d%c",cc[kk].data,' ');
if (cc[kk].lchild!=0)
xx(cc[kk].lchild,cc);
if (cc[kk].rchild!=0)
xx(cc[kk].rchild,cc);
}
}
//中序序列
void zx(long kk,struct BinaryTree cc[])
{
if (cc[kk].data!=0)
{
if (cc[kk].lchild!=0)
zx(cc[kk].lchild,cc);
printf("%d%c",cc[kk].data,' ');
if (cc[kk].rchild!=0)
zx(cc[kk].rchild,cc);
}
}
//后序序列
void hx(long kk,struct BinaryTree cc[])
{
if (cc[kk].data!=0)
{
if (cc[kk].lchild!=0)
hx(cc[kk].lchild,cc);
if (cc[kk].rchild!=0)
hx(cc[kk].rchild,cc);
printf("%d%c",cc[kk].data,' ');
}
}

 基于混合遗传算法的水电站经济运行
基于混合遗传算法的水电站经济运行