最优二叉树算法
衡量一个算法的优劣有许多因素,效率就是其中之一。而效率指的就是算法的执行时间。提高效率是软件开发必须注重的问题。对同一个问题往往有多个算法可以解决,在同等条件下,执行时间短的算法其效率是最高的。从霍夫曼树的定义以及霍夫曼算法出发,介绍如何构造霍夫曼树以及利用霍夫曼算法优化程序设计的原理,重点讨论在判定类问题中利用霍夫曼树可以建立最佳判定算法,提高程序的执行速度。
-
选择特殊符号
选择搜索类型
请输入搜索
衡量一个算法的优劣有许多因素,效率就是其中之一。而效率指的就是算法的执行时间。提高效率是软件开发必须注重的问题。对同一个问题往往有多个算法可以解决,在同等条件下,执行时间短的算法其效率是最高的。从霍夫曼树的定义以及霍夫曼算法出发,介绍如何构造霍夫曼树以及利用霍夫曼算法优化程序设计的原理,重点讨论在判定类问题中利用霍夫曼树可以建立最佳判定算法,提高程序的执行速度。
从上述算法中可以看出,F实际上是森林,该算法的思想是不断地进行森林F中的二叉树的"合并",最终得到哈夫曼树。
在构造哈夫曼树时,可以设置一个结构数组HuffNode保存哈夫曼树中各结点的信息,根据二叉树的性质可知,具有n个叶子结点的哈夫曼树共有2n-1个结点,所以数组HuffNode的大小设置为2n-1,数组元素的结构形式如下:
weight | lchild | rchild | parent |
其中,weight域保存结点的权值,lchild和rchild域分别保存该结点的左、右孩子结点在数组HuffNode中的序号,从而建立起结点之间的关系。为了判定一个结点是否已加入到要建立的哈夫曼树中,可通过parent域的值来确定。初始时parent的值为-1,当结点加入到树中时,该结点parent的值为其双亲结点在数组HuffNode中的序号,就不会是-1了。
构造哈夫曼树时,首先将由n个字符形成的n个叶结点存放到数组HuffNode的前n个分量中,然后根据前面介绍的哈夫曼方法的基本思想,不断将两个小子树合并为一个较大的子树,每次构成的新子树的根结点顺序放到HuffNode数组中的前n个分量的后面。
下面给出哈夫曼树的构造算法。
const maxvalue= 10000; {定义最大权值}
maxleat=30; {定义哈夫曼树中叶子结点个数}
maxnode=maxleaf*2-1;
type HnodeType=record
weight: integer;
parent: integer;
lchild: integer;
rchild: integer;
end;
HuffArr:array[0..maxnode] of HnodeType;
var ……
procedure CreatHaffmanTree(var HuffNode: HuffArr); {哈夫曼树的构造算法}
var i,j,m1,m2,x1,x2,n: integer;
begin
readln(n); {输入叶子结点个数}
for i:=0 to 2*n-1 do {数组HuffNode[ ]初始化}
begin
HuffNode.weight=0;
HuffNode.parent=-1;
HuffNode.lchild=-1;
HuffNode.rchild=-1;
end;
for i:=0 to n-1 do read(HuffNode.weight); {输入n个叶子结点的权值}
for i:=0 to n-1 do {构造哈夫曼树}
begin
m1:=MAXVALUE; m2:=MAXVALUE;
x1:=0; x2:=0;
for j:=0 to n i-1 do
if (HuffNode[j].weight
begin m2:=m1; x2:=x1;
m1:=HuffNode[j].weight; x1:=j;
end
else if (HuffNode[j].weight
begin m2:=HuffNode[j].weight; x2:=j; end;
{将找出的两棵子树合并为一棵子树}
HuffNode[x1].parent:=n i; HuffNode[x2].parent:=n i;
HuffNode[n i].weight:= HuffNode[x1].weight HuffNode[x2].weight;
HuffNode[n i].lchild:=x1; HuffNode[n i].rchild:=x2;
end;
end;
在数据通讯中,经常需要将传送的文字转换成由二进制字符0,1组成的二进制串,我们称之为编码。例如,假设要传送的电文为ABACCDA,电文中只含有A,B,C,D四种字符,若这四种字符采用表7.3 (a)所示的编码,则电文的代码为000010000100100111 000,长度为21。在传送电文时,我们总是希望传送时间尽可能短,这就要求电文代码尽可能短,显然,这种编码方案产生的电文代码不够短。表7.3 (b)所示为另一种编码方案,用此编码对上述电文进行编码所建立的代码为00010010101100,长度为14。在这种编码方案中,四种字符的编码均为两位,是一种等长编码。如果在编码时考虑字符出现的频率,让出现频率高的字符采用尽可能短的编码,出现频率低的字符采用稍长的编码,构造一种不等长编码,则电文的代码就可能更短。如当字符A,B,C,D采用表7.3 (c)所示的编码时,上述电文的代码为0110010101110,长度仅为13。
表a、表b、表c、表d(从下图的上下顺序依次列出)
字符 | 编码 |
A | 000 |
B | 010 |
C | 100 |
D | 111 |
字符 | 编码 |
A | 00 |
B | 01 |
C | 10 |
D | 11 |
字符 | 编码 |
A | 0 |
B | 110 |
C | 10 |
D | 111 |
字符 | 编码 |
A | 01 |
B | 010 |
C | 001 |
D | 10 |
表3 字符的四种不同的编码方案
哈夫曼树可用于构造使电文的编码总长最短的编码方案。具体做法如下:设需要编码的字符集合为{d1,d2,…,dn},它们在电文中出现的次数或频率集合为{w1,w2,…,wn},以d1,d2,…,dn作为叶结点,w1,w2,…,wn作为它们的权值,构造一棵哈夫曼树,规定哈夫曼树中的左分支代表0,右分支代表1,则从根结点到每个叶结点所经过的路径分支组成的0和1的序列便为该结点对应字符的编码,我们称之为哈夫曼编码。
在哈夫曼编码树中,树的带权路径长度的含义是各个字符的码长与其出现次数的乘积之和,也就是电文的代码总长,所以采用哈夫曼树构造的编码是一种能使电文代码总长最短的不等长编码。
在建立不等长编码时,必须使任何一个字符的编码都不是另一个字符编码的前缀,这样才能保证译码的唯一性。例如表7.3 (d)的编码方案,字符A的编码01是字符B的编码010的前缀部分,这样对于代码串0101001,既是AAC的代码,也是ABD和BDA的代码,因此,这样的编码不能保证译码的唯一性,我们称之为具有二义性的译码。
然而,采用哈夫曼树进行编码,则不会产生上述二义性问题。因为,在哈夫曼树中,每个字符结点都是叶结点,它们不可能在根结点到其它字符结点的路径上,所以一个字符的哈夫曼编码不可能是另一个字符的哈夫曼编码的前缀,从而保证了译码的非二义性。
下面讨论实现哈夫曼编码的算法。实现哈夫曼编码的算法可分为两大部分:
(1)构造哈夫曼树;
(2)在哈夫曼树上求叶结点的编码。
求哈夫曼编码,实质上就是在已建立的哈夫曼树中,从叶结点开始,沿结点的双亲链域回退到根结点,每回退一步,就走过了哈夫曼树的一个分支,从而得到一位哈夫曼码值,由于一个字符的哈夫曼编码是从根结点到相应叶结点所经过的路径上各分支所组成的0,1序列,因此先得到的分支代码为所求编码的低位码,后得到的分支代码为所求编码的高位码。我们可以设置一结构数组HuffCode用来存放各字符的哈夫曼编码信息,数组元素的结构如下:
bit | start |
其中,分量bit为一维数组,用来保存字符的哈夫曼编码,start表示该编码在数组bit中的开始位置。所以,对于第i个字符,它的哈夫曼编码存放在HuffCode.bit中的从HuffCode.start到n的分量上。
求哈夫曼编码程序段
const Maxleaf=128; {定义最多叶结点数}
MaxNode=255; {定义最大结点数}
MaxBit=10; {定义哈夫曼编码的最大长度}
type HCodeType =record
bit: array[0..MaxBit] of integer;
start: integer;
end;
……
procedure HaffmanCode ; {生成哈夫曼编码}
var HuffNode: array[0..MaxNode] of HCodeType;
HuffCode: array[0..MaxLeaf] of HcodeType;
cd : HcodeType ;
i,j, c,p: integer ;
begin
HuffmanTree (HuffNode ); {建立哈夫曼树}
for i:=0 to n-1 do {求每个叶子结点的哈夫曼编码}
begin
cd.start:=n-1; c:=i;
p:=HuffNode[c].parent;
while p<>0 do {由叶结点向上直到树根}
if HuffNode
.lchild=c then cd.bit[cd.start]:=0
else cd.bit[cd.start]:=1;
dec (cd.start); c:=p;
p:=HuffNode[c].parent;
end;
for j:=cd.start 1 to n-1 do {保存求出的每个叶结点的哈夫曼编码和编码的起始位}
begin
HuffCode.bit[j]:=cd.bit[j];
HuffCode.start=cd.start;
end;
for i:=0 to n-1 do {输出每个叶子结点的哈夫曼编码}
begin
for j:=HuffCode.start 1 to n-1 do write(HuffCode.bit[j]:10);
writeln;
end;
end;
在实际应用中,常常要考虑一个问题:如何设计一棵二叉树,使得执行路径最短,即算法的效率最高。
例1.快递包裹的邮资问题
假设邮政局的包裹自动测试系统能够测出包裹的重量,如何设计一棵二叉树将包裹根据重量及运距进行分类从而确定邮资。
国内快递包裹资费 单位:元
(2004年1月1日起执行)
运距(公里) | 首重1000克 | 5000克以内续重每500克 | 5001克以上续重每500克 |
<=500 | 5.00 | 2.00 | 1.00 |
<=1000 >500 | 6.00 | 2.50 | 1.30 |
<=1500 >1000 | 7.00 | 3.00 | 1.60 |
<=2000 >1500 | 8.00 | 3.50 | 1.90 |
<=2500 >2000 | 9.00 | 4.00 | 2.20 |
<=3000 >2500 | 10.00 | 4.50 | 2.50 |
<=4000 >3000 | 12.00 | 5.50 | 3.10 |
<=5000 >4000 | 14.00 | 6.50 | 3.70 |
<=6000 >5000 | 16.00 | 7.50 | 4.30 |
>6000 | 20.00 | 9.00 | 6.00 |
表1 国家邮政局制定的快递包裹参考标准
根据表1可以制定出许多种二叉树,但不同的二叉树判定的次数可能不一样,执行的效率也不同。
铁球分类
现有一批球磨机上的铁球,需要将它分成四类:直径不大于20的属于第一类;直径大于20而不大于50的属于第二类;直径大于50而不大于100的属于第三类;其余的属于第四类;假定这批球中属于第一、二、三、四类铁球的个数之比例是1:2:3:4。
我们可以把这个判断过程表示为 图1中的两种方法:
最优二叉树算法
两种判断二叉树示意图
那么究竟将这个判断过程表示成哪一个判断框,才能使其执行时间最短呢?让我们对上述判断框做一具体的分析。
假设有1000个铁球,则各类铁球的个数分别为:100、200、300、400;
对于图7.1中的上图和下图比较的次数分别如表所示:
左图 和下图
序号 | 比较式 | 比较次数 |
1 | a<20 | 1000 |
2 | a<50 | 900 |
3 | a<=100 | 700 |
合计 | 2600 |
序号 | 比较式 | 比较次数 |
1 | a>100 | 1000 |
2 | a>50 | 600 |
3 | a<=20 | 300 |
合计 | 1900 |
表2 两种判断二叉树比较次数
过上述分析可知,图1中右图所示的判断框的比较次数远远小于左图所示的判断框的比较次数。为了找出比较次数最少的判断框,将涉及到树的路径长度问题。
二叉树在计算机科学中,二叉树是每个结点最多有两个子树的有序树。通常子树的根被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用作二叉查找树和二叉堆。二叉...
设一棵二叉树中有3个叶子结点,有8个度为1的结点,则该二叉树中总的结点数为() A12 B13 C14 D15
因为叶子节点与度为2的结点的关系是:n0=n2+1;因为 n0=3,所以 n2=2;总的结点数:n=n0+n1+n2=3+8+2=13希望能帮助你
山水环保机械养殖场污水处理设备,养殖场污水自流进入格栅池,去除污水中固体悬浮物,然后流至调节池,有效地进行水量和水质调节,经提升泵送入A/O工艺池,养殖场污水及从沉淀池排出的含磷回流污泥同步进入厌氧反...
最优二叉树,也称哈夫曼(Haffman)树,是指对于一组带有确定权值的叶结点,构造的具有最小带权路径长度的二叉树。
那么什么是二叉树的带权路径长度呢?
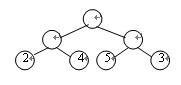
在前面我们介绍过路径和结点的路径长度的概念,而二叉树的路径长度则是指由根结点到所有叶结点的路径长度之和。如果二叉树中的叶结点都具有一定的权值,则可将这一概念加以推广。设二叉树具有n个带权值的叶结点,那么从根结点到各个叶结点的路径长度与相应结点权值的乘积之和叫做二叉树的带权路径长度,记为:
WPL= Wk·Lk
其中Wk为第k个叶结点的权值,Lk 为第k个叶结点的路径长度。如图7.2所示的二叉树,它的带权路径长度值WPL=2×2+4×2+5×2+3×2=28。
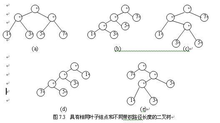
在给定一组具有确定权值的叶结点,可以构造出不同的带权二叉树。例如,给出4个叶结点,设其权值分别为1,3,5,7,我们可以构造出形状不同的多个二叉树。这些形状不同的二叉树的带权路径长度将各不相同。图7.3给出了其中5个不同形状的二叉树。
这五棵树的带权路径长度分别为:
(a)WPL=1×2+3×2+5×2+7×2=32
(b)WPL=1×3+3×3+5×2+7×1=29
(c)WPL=1×2+3×3+5×3+7×1=33
(d)WPL=7×3+5×3+3×2+1×1=43
(e)WPL=7×1+5×2+3×3+1×3=29
最优二叉树算法
最优二叉树算法
由此可见,由相同权值的一组叶子结点所构成的二叉树有不同的形态和不同的带权路径长度,那么如何找到带权路径长度最小的二叉树(即哈夫曼树)呢?根据哈夫曼树的定义,一棵二叉树要使其WPL值最小,必须使权值越大的叶结点越靠近根结点,而权值越小的叶结点越远离根结点。
哈夫曼(Haffman)依据这一特点于1952年提出了一种方法,这种方法的基本思想是:
(1)由给定的n个权值{W1,W2,…,Wn}构造n棵只有一个叶结点的二叉树,从而得到一个二叉树的集合F={T1,T2,…,Tn};
(2)在F中选取根结点的权值最小和次小的两棵二叉树作为左、右子树构造一棵新的二叉树,这棵新的二叉树根结点的权值为其左、右子树根结点权值之和;
(3)在集合F中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到集合F中;
(4)重复(2)(3)两步,当F中只剩下一棵二叉树时,这棵二叉树便是所要建立的哈夫曼树。
在本章的引入部分,两个例子都是判定问题,这两个判定问题都可以通过构造哈夫曼树来优化判定,以达到总的判定次数最少。
再如,要编制一个将百分制转换为五级分制的程序。显然,此程序很简单,只要利用条件语句便可完成。
程序段
if a<60 then b:='bad'
else if a<70 then b:='pass'
else if a<80 then b:='general'
else if a<90 then b:='good'
else b:='excellent';
如果上述程序需反复使用,而且每次的输入量很大,则应考虑上述程序的质量问题,即其操作所需要的时间。因为在实际中,学生的成绩在五个等级上的分布是不均匀的,假设其分布规律如表4所示:
分数 | 0-59 | 60-69 | 70-79 | 80-89 | 90-100 |
比例数 | 0.05 | 0.15 | 0.40 | 0.30 | 0.10 |
表4 分数段的分布频率
则80%以上的数据需进行三次或三次以上的比较才能得出结果。假定以5,15,40,30和10为权构造一棵有五个叶子结点的哈夫曼树,它可使大部分的数据经过较少的比较次数得出结果。但由于每个判定框都有两次比较,将这两次比较分开,得到新的判定树,按此判定树可写出相应的程序。请您自己画出此判定树。
假设有10000个输入数据,若上程序段的判定过程进行操作,则总共需进行31500次比较;而若新判定树的判定过程进行操作,则总共仅需进行22000次比较。

 支持向量机的二叉树多分类算法在变压器故障诊断中的应用
支持向量机的二叉树多分类算法在变压器故障诊断中的应用
支持向量机的二叉树多分类算法在变压器故障诊断中的应用
支持向量机最初只能用以解决二分类问题,对于多类故障,只能通过组合二分类器间接应用于多类分类问题。本文提出一种基于二叉树多分类算法对变压器中常见故障进行了模式识别,并与传统多分类算法作对比。根据svm理论结合二叉树方法建立变压器故障诊断模型,通过VS2008对其进行了验证,结果表明该方法能有效地、准确地识别故障模式,具有较高的推广性。
一种基于有序二叉树的变量池的设计和应用
一种基于有序二叉树的变量池的设计和应用
分层模式在软件开发中有着广泛的应用,必然使各层之间产生频繁的数据交互,从而导致软件性能大大下降。针对上述问题,本文提出一种基于有序二叉树的变量池的解决方案,软件的配置信息以及各层之间的交互数据保存在变量池中,对变量的所有操作都基于变量池,通过变量池的使用,既方便了各层之间数据交互,也简化了各层之间的接口设计。基于该方案,本文最后实现了一个银行自助终端系统。
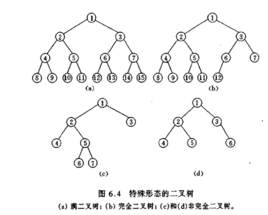
如果一棵具有n个结点的深度为k的二叉树,它的每一个结点都与深度为k的满二叉树中编号为1~n的结点一一对应,这棵二叉树称为完全二叉树。
可以根据公式进行推导,假设n0是度为0的结点总数(即叶子结点数),n1是度为1的结点总数,n2是度为2的结点总数,则 ①n= n0+n1+n2 (其中n为完全二叉树的结点总数);又因为一个度为2的结点会有2个子结点,一个度为1的结点会有1个子结点,除根结点外其他结点都有父结点,所以②n= 1+n1+2*n2 ;由①、②两式把n2消去得:n= 2*n0+n1-1,由于完全二叉树中度为1的结点数只有两种可能0或1,由此得到n0=n/2 或 n0=(n+1)/2。
简便来算,就是 n0=n/2,其中n为奇数时(n1=0)向上取整;n为偶数时(n1=1)。可根据完全二叉树的结点总数计算出叶子结点数。
由于网络所有可能的划分数量是巨大的,假设网络的结点数和边数分别为n和m,则所有可能的社区划分数是一个以n为指数的数。因此,在所有可能的划分中找出最优划分是一个NP-hard问题。针对这一问题,目前一些相应算法已被提出,其可以在合理的时间内找出模块度最大化的近似最优划分。
模块度最大化问题是一个经典的最优化问题,Mark NewMan 基于贪心思想提出了模块度最大化的贪心算法FN 。贪心思想的目标是找出目标函数的整体最优值或者近似最优值,它将整体最优化问题分解为局部最优化问题,找出每个局部最优值,最终将局部最优值整合成整体的近似最优值。FN算法将模块度最优化问题分解为模块度局部最优化问题,初始时,算法将网络中的每个结点都看成独立的小社区。然后,考虑所有相连社区两两合并的情况,计算每种合并带来的模块度的增量。基于贪心原则,选取使模块度增长最大或者减小最少的两个社区,将它们合并成一个社区。如此循环迭代,直到所有结点合并成一个社区。随着迭代的进行,网络总的模块度是不断变化的,在模块度的整个变化过程中,其最大值对应网络的社区划分即为近似的最优社区划分。
贪心算法FN具体步骤:
去掉网络中所有的边,网络的每个结点都单独作为一个社区;网络中的每个连通部分作为一个社区,将还未加入网络的边分别重新加回网络,每次加入一条边,如果加入网络的边连接了两个不同的社区,则合并两个社区,并计算形成新社区划分的模块度增量。选择使模块度增量最大或者减小最少的两个社区进行合并。如果网络的社区数大于1,则返回步骤(2)继续迭代,否则转到步骤(4);遍历每种社区划分对应的模块度值,选取模块度最大的社区划分作为网络的最优划分。该算法中,需要注意的是,每次加入的边只是影响网络的社区划分,而每次计算网络划分的模块度时,都是在网络完整的拓扑结构上进行,即网络所有的边都存在的拓扑结构上。
为了降低算法的时间复杂度,Vincent Blondel等人提出了另一种层次贪心算法 。该算法包括两个阶段,第一阶段合并社区,算法将每个结点当作一个社区,基于模块度增量最大化标准决定你哪些邻居社区应该被合并。经过一轮扫描后开始第二阶段,算法将第一阶段发现的所有社区重新看成结点,构建新的网络,在新网络上重复进行第一阶段,这两个阶段重复运行,直到网络社区划分的模块度不再增长,得到网络的社区近似最优划分。
这个简单算法具有一下几个优点:首先,算法的步骤比较直观并且易于实现;其次,算法不需要提前设定网络的社区数,并且该算法可以呈现网络的完整的分层社区结构,能够发现在线社交网络的分层的虚拟社区结构,获得不同分辨率的虚拟社区;再次,计算机模拟实验显示,在稀疏网络上,算法是时间复杂度是线性的,在合理的时间内可以处理结点数超过10^9的网络,因此十分适合在线社交网络这样超大规模的负责网络中虚拟社区的发现。
是程序算法中的一种算法模式。
在二叉树中出现空的子树(包括树叶)上增加空的树叶,使其成为满二叉树的二叉树称之为扩充二叉树。